Project Delivery
Project Delivery
Now, Let's move to project delivery part.
Can we do this project?
When we first talk to a user, how do we decide if we can recommend HyperBDR disaster recovery to them?
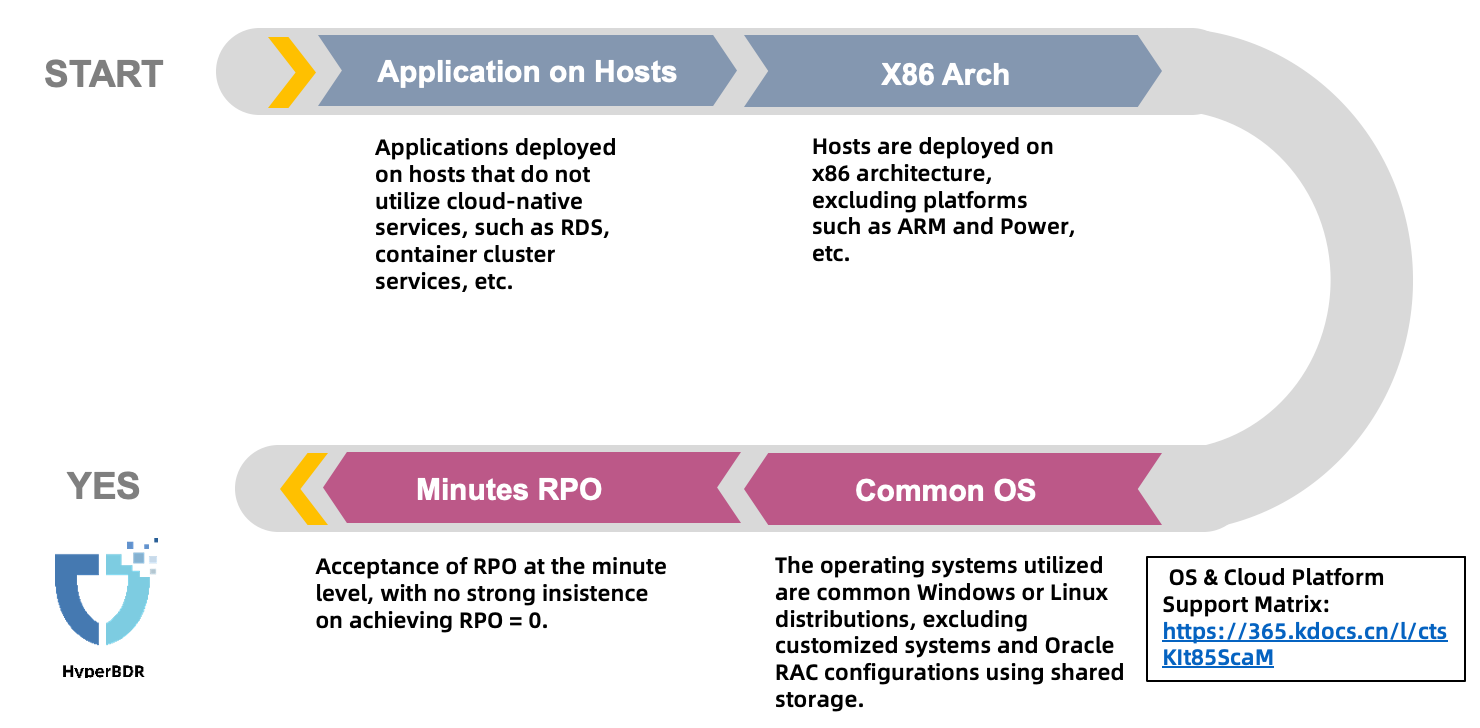
Here's a simple way to decide:
- Firstly, if the user's business systems are running on servers and they need disaster recovery, then they might be a potential customer. If they use Oracle RAC or cloud-native relational database services partially, they might need a hybrid solution we mentioned before. If they only want to protect Oracle or use cloud-native services entirely, they might not be able to use Hyper BDR for disaster recovery.
- Secondly, currently, HyperBDR mainly works with X86 architecture servers. It doesn't work with ARM or IBM Power series for now.
- Thirdly, they should be using common operating systems like CentOS, Redhat, SUSE, Windows, etc. However, some operating systems provided by cloud providers might be customized with modified kernels, so standard HyperBDR products may not work directly, and custom development might be needed.
- Finally, if the user can accept a recovery point objective (RPO) of minutes, then they are likely potential users of HyperBDR.
Project Gantt Overview
To facilitate understanding of the entire project delivery process, we use Gantt charts for illustration:
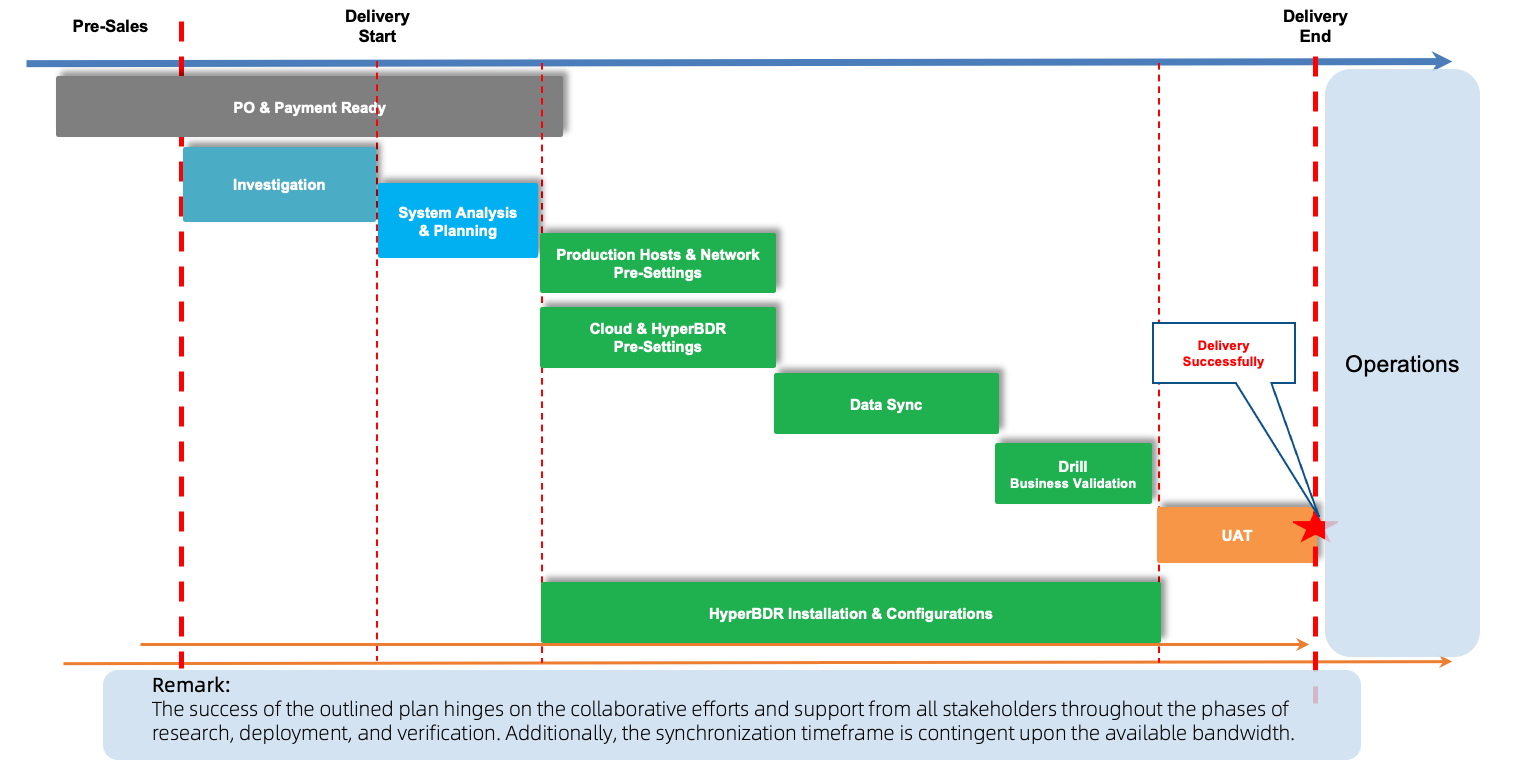
After confirming that HyperBDR can meet the customer's requirements, we need to conduct research on the customer's business systems to determine the scope of support.
Based on the research findings, we determine the types of cloud storage to be used based on the requirements for disaster recovery networks, RPO, and RTO, ultimately forming a delivery plan.
Once the project enters the delivery phase, pre-configuration is conducted for the user's source end and network environment according to the checklist. Simultaneously, network configuration and HyperBDR installation and configuration are performed in the cloud.
After the installation and configuration of the production environment and HyperBDR are completed, we enter the product usage phase, synchronizing data according to the schedule. The amount of data synchronized depends on factors such as data volume and bandwidth.
After the initial synchronization is completed, it is recommended to conduct a drill to confirm the integrity of disaster recovery data.
Finally, HyperBDR is monitored, and alarm configurations are made, completing the project delivery and entering the maintenance phase.
Investigation
Disaster recovery research mainly involves three aspects: host, network, and applications.
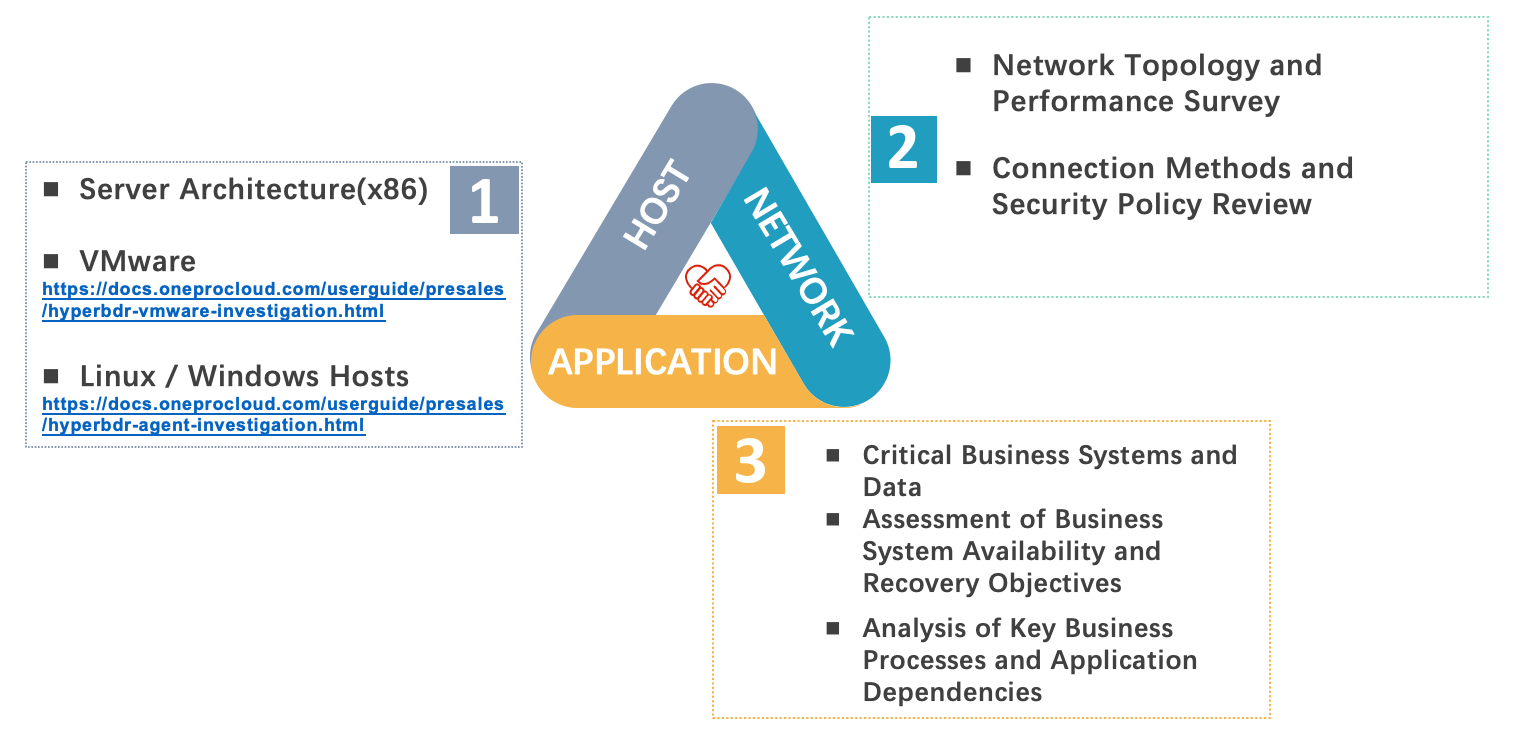
When conducting host research, we need to gather detailed information about the hosts to determine if HyperBDR fully supports them. We can use methods provided in the official HyperBDR documentation for this.
Network research aims to determine the existing network topology and bandwidth situation of the users. With this information, we can plan the disaster recovery network on the cloud platform and decide if VPN or dedicated connections are needed between the user's production and backup sites.
Application system research can be carried out concurrently with host research. It mainly involves determining the importance of user business systems and configuring different disaster recovery strategies in HyperBDR based on their importance levels. Additionally, we need to establish the sequence for taking over systems during disaster recovery based on their interdependencies.
Useful Links
- OS & Cloud Platform Support Matrix
- Linux Agent Compatibility & Limitations
- Windows Agent Compatibility & Limitations
- VMware Agentless Compatibility & Limitations
RPO & RTO Planning
Planning for RPO and RTO needs to be based on the requirements of the user's business systems. Here are some best practices for RPO and RTO planning, which you can read by clicking the link provided.
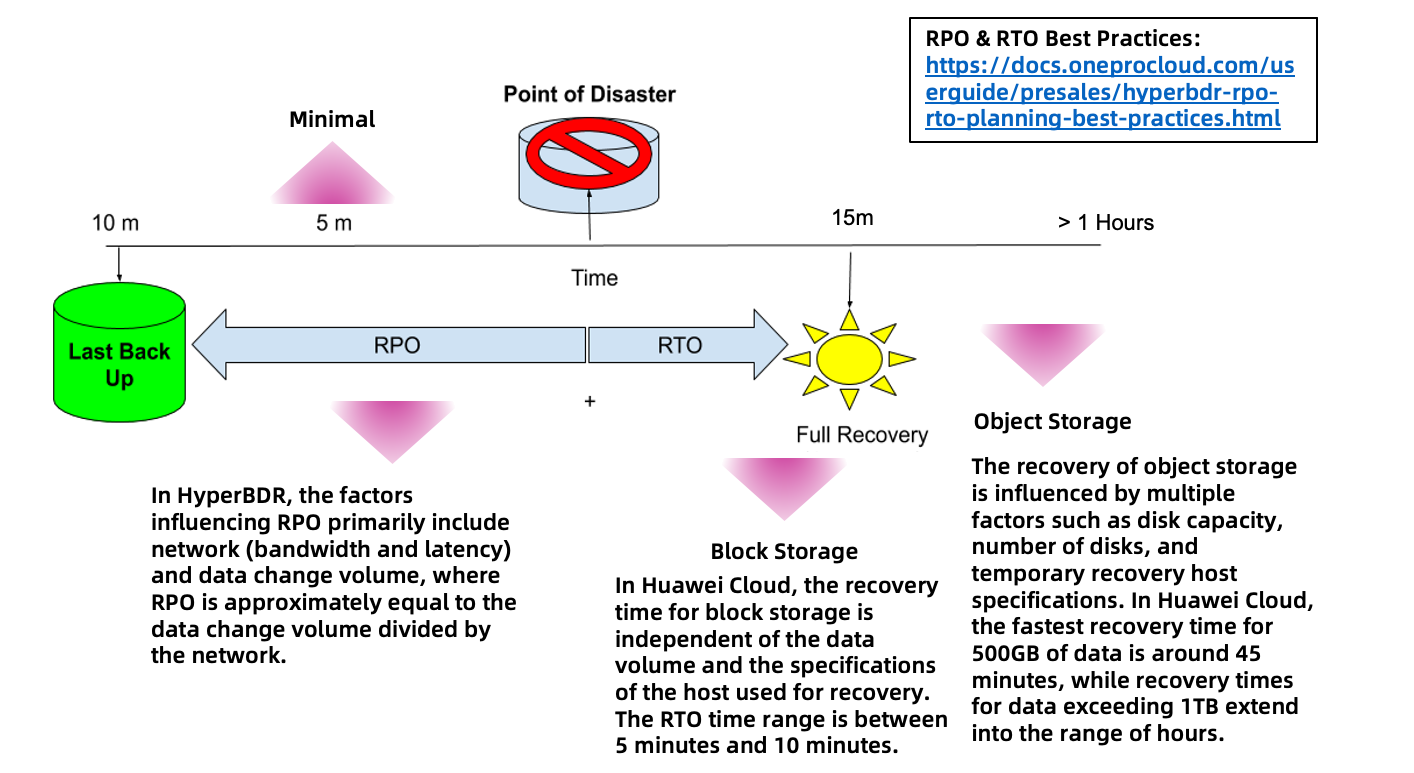
Currently, the minimum RPO time for HyperBDR is 5 minutes, and it needs to be matched with the corresponding network bandwidth based on the size of data increments.
In terms of RTO planning, the Huawei Cloud block storage mode is independent of data volume, with recovery times always within 15 minutes. However, the object storage mode is related to data volume. Specific indicator parameters can be referred to in the content of best practices.
Based on the expected RTO of the user's business system, choose the appropriate storage type reasonably.
Workload DR Network Planning
User's disaster recovery network planning is directly related to the connection between the production network and the disaster recovery network. Here, we also provide some best practice content for your reference. However, network planning is often a complex topic that requires experienced network engineers to make reasonable plans based on actual conditions. Here, based on some typical cases, we provide some suggestions:
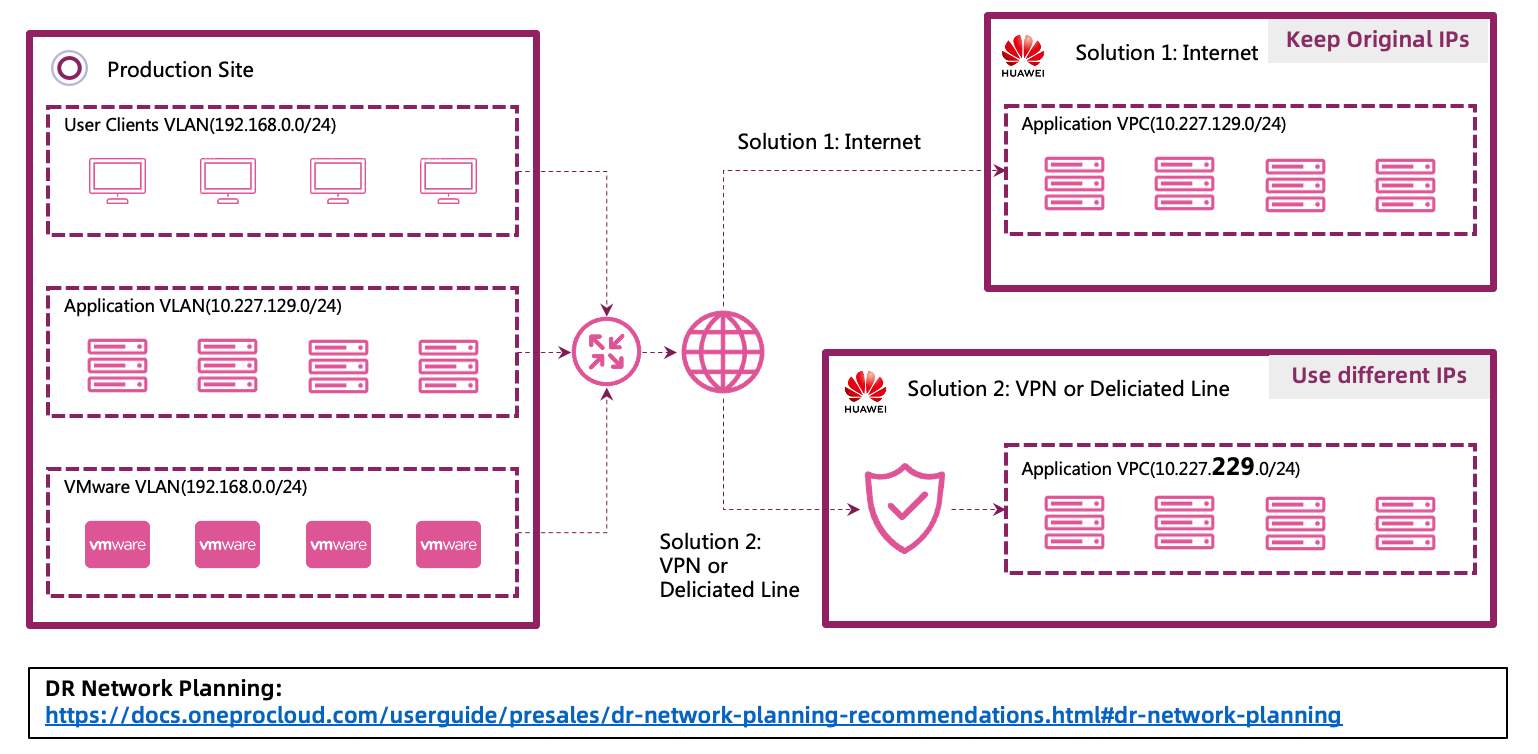
If the user synchronizes data using the public network, the addresses of the production network and the disaster recovery network can remain the same.
If the user connects the production center and the disaster recovery center using VPNs and dedicated lines, it is recommended to choose different takeover networks. This can effectively avoid the impact on the production environment during drills or takeovers.
Use Checklist for Deployment
As we officially enter the deployment phase, it's crucial to use a Checklist along with the delivery process. The Checklist provides clear guidance for users to follow through each step of the operation.

When selecting the Checklist, start by choosing based on the type of source system. Then, select the storage type of the cloud platform being used, followed by deciding on the network connection, whether it's through the public network or via VPN or dedicated lines. Finally, locate the corresponding Checklist.
The Checklist is presented in a form format and needs to be completed step by step according to the guidance to finish the installation and configuration work of HyperBDR.