RPO & RTO Best Practices
RPO & RTO Best Practices
How to Plan Reasonable RPO and RTO Times
When planning the Recovery Time Objective (RTO) and Recovery Point Objective (RPO) for a business system, various factors need to be considered, such as Service Level Agreements (SLA) and external compliance requirements. Different disaster recovery methods directly impact recovery costs. So, how do you choose the most cost-effective disaster recovery solution? Typically, it can be planned based on different business continuity needs:
| Tier | Application Type | RTO | RPO | Description |
|---|---|---|---|---|
| Tier-0 | Core Application | Near zero | Near zero | Critical to the business, almost no tolerance for downtime or data loss |
| Tier-1 | Critical Application | 15 minutes | Near zero | Essential for business operations, requires fast recovery and minimal data loss |
| Tier-2 | Important Application | Typically 4 hours | Typically 2 hours | Significant impact on operations, needs reasonable recovery time and data loss tolerance |
| Tier-3 | Other Application | Typically 8-24 hours | Typically 4 hours | Less impact on operations, allows longer recovery time and more data loss |
For Tier-0 core applications, relying solely on external tools often cannot meet high availability requirements. Therefore, it is usually necessary to achieve high reliability at the application level to ensure that the system can run continuously under any circumstances. This high-reliability architecture is widely used in internet sectors such as financial services, e-commerce, online gaming, and cloud computing to ensure business continuity and stable user experience. Implementing this architecture typically involves using redundant hardware and network configurations, load balancing, real-time data backups, and failover mechanisms to create a completely interruption-free high-reliability service system. The high-reliability architecture supporting Tier-0 core applications significantly increases resource and labor costs, potentially reaching 2 to 5 times or more of the original production system. Therefore, if a business has sufficient financial and human resources, choosing this method for its disaster recovery solution is a very reasonable choice.
For Tier-1 critical applications, there are high requirements for business continuity. Therefore, a hybrid approach is usually adopted to build a disaster recovery system that balances disaster recovery costs with budget investments. This hybrid approach enables disaster recovery at the infrastructure level without changing the existing software architecture, allowing businesses to ensure data security and system availability while controlling overall disaster recovery costs.
For example, in a typical three-tier architecture, stateful data is often stored in a database. In the disaster recovery solution design, native replication solutions at the database level, such as Oracle Data Guard, can be used to achieve zero data loss. Additionally, HyperBDR can protect the hosts and enable one-click recovery in the cloud. By meeting the Service Level Agreement (SLA) requirements, this approach effectively controls the investment in disaster recovery resources. Therefore, this solution is the preferred choice for disaster recovery in critical applications.
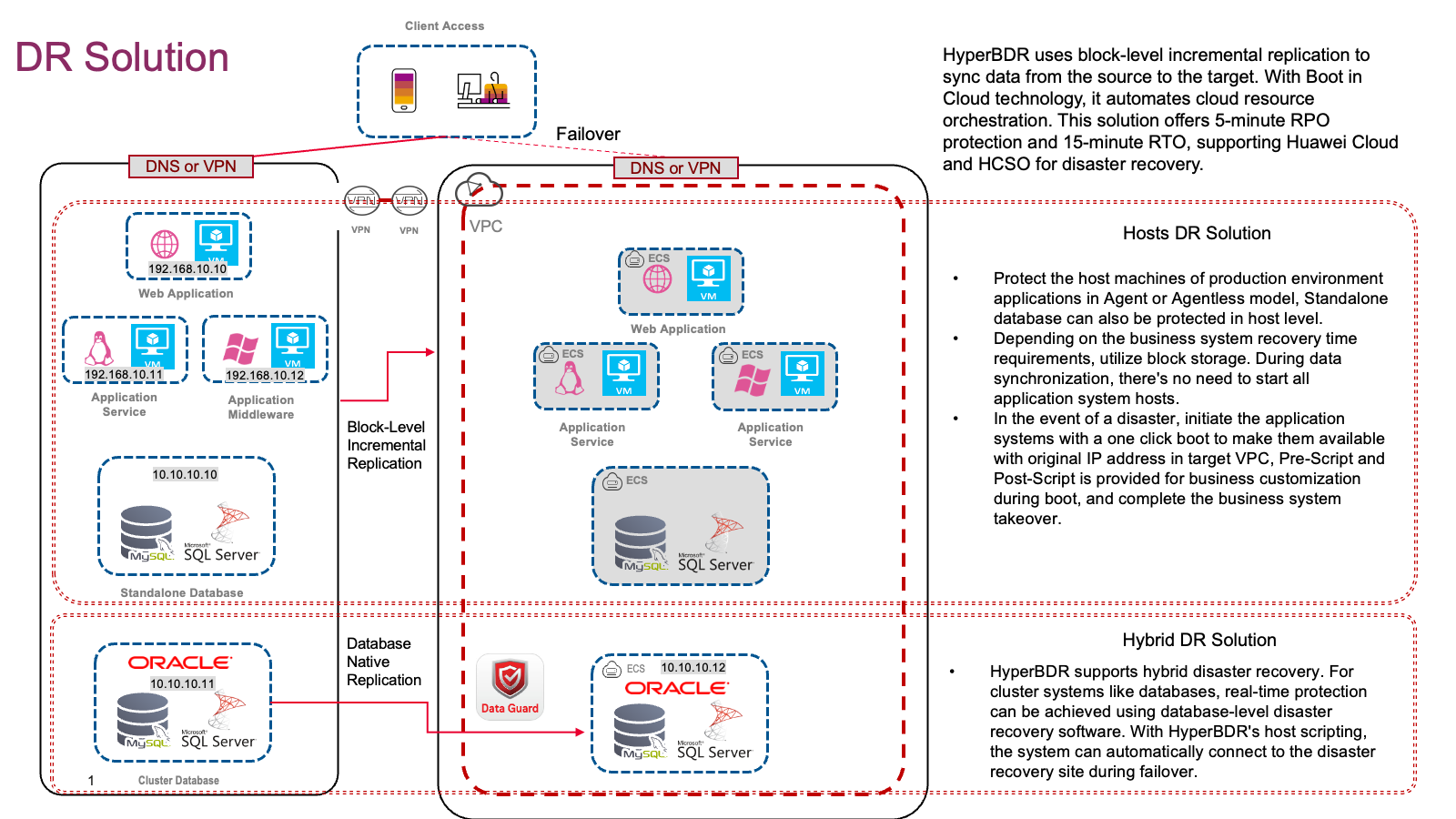
For Tier-2 important applications, there is some tolerance for RPO and RTO times, so it is recommended to use disaster recovery software to build the disaster recovery system. By using mature disaster recovery software like HyperBDR to protect all hosts, companies can achieve automated backup and recovery, simplifying operations. HyperBDR implements disaster recovery in a cloud-native way, effectively using cloud resource characteristics to reduce cloud resource costs by 80% compared to traditional disaster recovery software in the cloud. Additionally, it provides fast recovery capabilities, fully meeting user requirements for business recovery time.
Companies can set up regular incremental backups to minimize the risk of data loss and reduce storage costs. Although Tier-2 applications have relatively relaxed requirements for recovery time and recovery point, it is still essential to ensure that key business functions can be quickly restored during a disaster. Using HyperBDR not only effectively lowers implementation costs but also meets the needs for flexibility and scalability, allowing businesses to adjust and optimize as they grow. This way, companies can ensure the availability and business continuity of important applications while maintaining cost-effectiveness.
For Tier-3 other applications, the RPO and RTO requirements are more relaxed, while there is greater sensitivity to disaster recovery investments. Therefore, the ideal solution is to use a unified system that meets both backup and disaster recovery needs. In this case, HyperBDR supports cloud-native object storage, effectively balancing the gap between demand and cost. By leveraging cloud-native object storage, companies can achieve efficient data backup and recovery, reducing reliance on physical storage resources. This not only lowers storage costs but also enhances data accessibility and security.
The flexibility of HyperBDR allows businesses to adjust according to actual needs, ensuring that backup and disaster recovery requirements are met in different business scenarios. Additionally, HyperBDR's unified management interface enables IT staff to easily monitor and manage backup and disaster recovery processes, reducing operational complexity. This integrated solution is particularly suitable for Tier-3 applications, as it provides necessary reliability and flexibility while maintaining cost-effectiveness, helping businesses effectively address potential data loss risks.
Basic Concept
About RPO & RTO
When it comes to Disaster Recovery, two key concepts are RPO (Recovery Point Objective) and RTO (Recovery Time Objective). They are critical performance metrics in disaster recovery planning, used to measure the recoverability and business continuity of systems in the event of a catastrophic incident.
Recovery Point Objective (RPO)
RPO refers to the time frame within which a system can tolerate data loss in the event of a failure or catastrophic incident. In other words, RPO defines the maximum amount of data loss that the business can tolerate. Usually measured in units of time (such as hours or minutes), the choice of RPO depends on the business's real-time data requirements and the acceptable risk of data loss. Lower RPO values indicate that the system can back up data more frequently, reducing the amount of data lost in the event of a catastrophic incident.
Factors involved in calculating RPO include:
Business criticality: Systems critical to business operations will have a higher RPO, while less critical systems will have a lower RPO.
Data change rate: Systems with a high data change rate typically have a higher RPO, while systems with a lower data change rate have a lower RPO.
Backup frequency: Higher backup frequencies result in lower RPO.
Recovery time: Shorter recovery time requirements lead to lower RPO.
Backup storage: If backup storage is more reliable and recovery time is shorter, RPO will remain lower.
Compliance and regulatory requirements: Some industries have specific requirements for data recovery and retention, which may affect RPO.
IT budget and resources: An organization's IT budget and available resources can impact RPO.
To establish a robust disaster recovery plan, it's essential to consider the above factors when calculating RPO.
Recovery Time Objective (RTO)
RTO (Recovery Time Objective) refers to the maximum time required for a system to recover to normal operation after a catastrophic event. It is a time window that defines the maximum acceptable downtime for the business. The selection of RTO is typically based on the business's continuity requirements, indicating how quickly the business can resume normal operation after a catastrophic event. A shorter RTO indicates a higher level of business continuity, as the system can recover more quickly from a disaster, minimizing business interruption.
The RTO time is equal to the sum of the Host Recovery Time and Business Recovery Time.
Host Recovery Time: This refers to the time required to recover the system after a failure or catastrophic event. This may involve steps such as restarting the host, loading the operating system, and applications.
Business Recovery Time: This refers to the time required for the business to fully recover to normal operation after the host has been recovered. This includes ensuring that applications and services are fully available and that business functions are executing normally.
Disaster recovery costs and their relationship with RPO and RTO:
The pursuit of a lower RPO often requires more frequent data backup and replication, leading to an increase in storage, bandwidth, and operational costs. Real-time or near-real-time backup demands greater resource investment, resulting in a corresponding increase in costs while achieving a low RPO. Conversely, higher RPO implies longer backup intervals, reducing the frequency of backup and replication, thereby lowering hardware and network costs.
Achieving a shorter RTO typically demands more resource investment, including high-availability systems, redundant equipment, and complex architecture, which increases hardware, software, and maintenance costs. On the contrary, opting for a longer RTO allows for more downtime, reducing reliance on high-availability systems and consequently lowering associated costs.
How to choose reasonable RPO and RTO?
It is recommended to adopt a flexible disaster recovery plan based on business needs and cost tolerance. Flexibly choose RPO and RTO based on the importance of business systems. Provide higher investment for critical business systems to minimize potential data loss and downtime, while secondary systems can accept some sacrifices to achieve cost reduction. For critical business systems, pursuing low RPO and short RTO may require higher investment, whereas secondary systems can tolerate higher RPO and longer RTO to reduce costs.
HyperBDR RPO & RTO Best Practices
HyperBDR RPO & RTO
| Storage Type | Cloud Platform | Min. RPO | Min. RTO | Notes |
|---|---|---|---|---|
| Block Storage | Huawei Cloud | 5 Minutes | 5 Minutes - 10 Minutes | In Huawei Cloud, the recovery time for block storage is independent of the data volume, with a restoration time range of 5-10 minutes. |
| Object Storage | Huawei Cloud | 5 Minutes | 5 minutes to hours (depending on the actual amount of data being recovered) | In Huawei Cloud, the Object Storage Recovery Time Objective (RTO) is influenced by multiple factors, including data volume and the specifications of the recovery host. For detailed calculation methods, please refer to the Best Practices for RTO Planning. |
Best Practices for RPO Calculation
RPO Calculation
In HyperBDR, the factors influencing RPO primarily include network (bandwidth and latency) and data change volume, where RPO is approximately equal to the data change volume divided by the network.
HyperBDR predominantly employs block-level differential capture technology to obtain the data change volume. This involves capturing the sum of changed blocks at the operating system's block level within a unit time range, which can be estimated based on the specific business scenario.
Network bandwidth and latency refer to the connection between the user's current environment and the cloud. Depending on the mode used, they are categorized as follows:
Block Storage: Network bandwidth and latency between the user's side and the synchronization gateway's public network in the cloud.
Object Storage: Network bandwidth and latency between the user's side and the cloud's object storage.
Assuming the user's production data allocation capacity is 1TB, we outline the bandwidth and data change volume under different RPO requirements.
| Data Volume (TB) | RPO Expectation (Minutes) | Data Change Rate (%) | Data Change Volume (GB) | Estimated Bandwidth (Mbps) |
|---|---|---|---|---|
| 1 | 5 | 5.00% | 51.20 | 1398 |
| 1 | 10 | 5.00% | 51.20 | 699 |
| 1 | 30 | 5.00% | 51.20 | 233 |
| 1 | 60 | 5.00% | 51.20 | 117 |
| 1 | 240 | 5.00% | 51.20 | 29 |
| 1 | 720 | 5.00% | 51.20 | 10 |
| 1 | 1440 | 5.00% | 51.20 | 5 |
Best Practices for RTO Calculation
Block Storage
In Huawei Cloud, the recovery time for block storage is independent of the data volume and the specifications of the host used for recovery. The RTO time range is between 5 minutes and 10 minutes. The following is a simulated test scenario using 1 TB capacity for reference in actual planning:
| Disk Count | Recovery Host Flavor | Disk Type | Recovery Host Duration (Minutes) |
|---|---|---|---|
| Single Disk(Usage Capacity 800 GB) Multiple Disks(Usage Capacity 1010 GB) | Unrestricted (Ensure that the selected host specifications can use the corresponding disk type) | High I/O(SAS) General Purpose SSD(GPSSD) Ultra-high I/O(SSD) Extreme SSD(ESSD) | 5 - 10 |
Object Storage
In Huawei Cloud, the Object Storage mode is influenced by several factors in terms of RTO time, primarily including:
Data Volume: The actual volume of data being recovered.
Number of Disks: When recovering from multiple disks simultaneously, the recovery time is approximately equal to the time taken for the maximum disk recovery.
Temporary Recovery Gateway Specification Configuration
During recovery with HyperBDR, a host is launched as a temporary recovery gateway for business recovery. The specifications of this host are set by the user in the disaster recovery configuration. Metrics such as CPU, memory, maximum bandwidth, and maximum packet send/receive capability in these specifications may affect the recovery speed.
Impact of Specifications on Disk Concurrent Recovery Speed: During the recovery process in HyperBDR, CPU and memory resources are required to decrypt and decompress (if enabled) object storage data before restoring it to block storage. By default, data recovery is performed concurrently, and each disk requires a minimum of 1 GB of memory for recovery. For example, using a specification of 2 cores and 4 GB of RAM, a maximum of 4 disks can undergo simultaneous recovery.
Volume Type: During recovery with HyperBDR, the data from object storage is recopied to block storage. Therefore, the selected volume type in the disaster recovery configuration also affects the recovery time.
Below are some common specification recommendations and the host recovery time for 1TB of effective data (i.e., entirely comprised of data) under different circumstances.
| Disk Count | Recovery Host Flavor | Disk Type | Recovery Host Duration (Minutes) |
|---|---|---|---|
| Single Disk(Usage capacity 100 GB) | Memory is less than or equal to 4GB Maximum bandwidth range: 1.5 - 4 Gbps | High I/O(SAS) General Purpose SSD(GPSSD) Ultra-high I/O(SSD) Extreme SSD(ESSD) | 20 Minutes(Ultra-high I/O, Extreme SSD) 25 Minutes(General Purpose SSD) 30 Minutes(High I/O) |
| Single Disk(Usage capacity 100 GB) | Memory is greater than 4GB Maximum bandwidth range: Greater than 4 Gbps | High I/O(SAS) General Purpose SSD(GPSSD) Ultra-high I/O(SSD) Extreme SSD(ESSD) | 30 Minutes(High I/O) 20 Minutes(Ultra-high I/O, Extreme SSD) |
| Single Disk(Usage capacity 500 GB) | Memory is less than or equal to 4GB Maximum bandwidth range: 1.5 - 4 Gbps | High I/O(SAS) General Purpose SSD(GPSSD) Ultra-high I/O(SSD) Extreme SSD(ESSD) | 1 Hour 30 Minutes(High I/O) 1 Hour 10 Minutes(Ultra-high I/O, Extreme SSD) |
| Single Disk(Usage capacity 500 GB) | Memory is greater than 4GB Maximum bandwidth range: Greater than 4 Gbps | High I/O(SAS) General Purpose SSD(GPSSD) Ultra-high I/O(SSD) Extreme SSD(ESSD) | 45 Minutes(Ultra-high I/O, Extreme SSD) 1 Hour 30 Minutes(High I/O) |
| Single Disk(Usage capacity 920 GB) Multiple Disks(Usage capacity 1010 GB) | Memory is less than or equal to 4GB Maximum bandwidth range: 1.5 - 4 Gbps | High I/O(SAS) General Purpose SSD(GPSSD) Ultra-high I/O(SSD) Extreme SSD(ESSD) | 2 Hours 10 Minutes(Ultra-high I/O, Extreme SSD) 2 Hours 20 Minutes(General Purpose SSD) 2 Hours 30 Minutes(High I/O) |
| Single Disk(Usage capacity 920 GB) Multiple Disks(Usage capacity 1010 GB) | Memory is greater than 4GB Maximum bandwidth range: Greater than 4 Gbps | General Purpose SSD(GPSSD) Ultra-high I/O(SSD) Extreme SSD(ESSD) | 1 Hour 15 Minutes(Ultra-high I/O, Extreme SSD) 1 Hour 35 Minutes(General Purpose SSD) |
Recommended Specifications for Object Storage Mode Disaster Recovery
Documentation for Huawei Cloud Computing Specifications: https://support.huaweicloud.com/intl/en-us/productdesc-ecs/ecs_01_0014.html
| Specifications | Recommendation |
|---|---|
| Memory is less than or equal to 4GB Maximum bandwidth range: 1.5 - 4 Gbps | General Computing S7 / S7n / S6 / Sn3 General Computing-plus C7n / C6 / C3ne / C3 High-performance computing H3 / Hc2 |
| Memory is greater than 4GB Maximum bandwidth range: Greater than 4 Gbps | General Computing Sn3 / S3 / S2 General Computing-plus C7 / aC7 / C7n / C6s / C6h / C6 / C3ne / C3 Memory-optimized M7 / aM7 / M7n / M6 / M6nl / M3ne / M3 / M2 Large-Memory E7 / E6 / E3 Disk-intensive D7 / D6 / D3 / D2 Ultra-high I/O Ir7 / I7 / aI7 / Ir7n / I7n / Ir3 / I3 High-Performance Computing H3 / Hc2 |
How to search for recommended series and specific specifications in the Huawei Cloud official documentation:
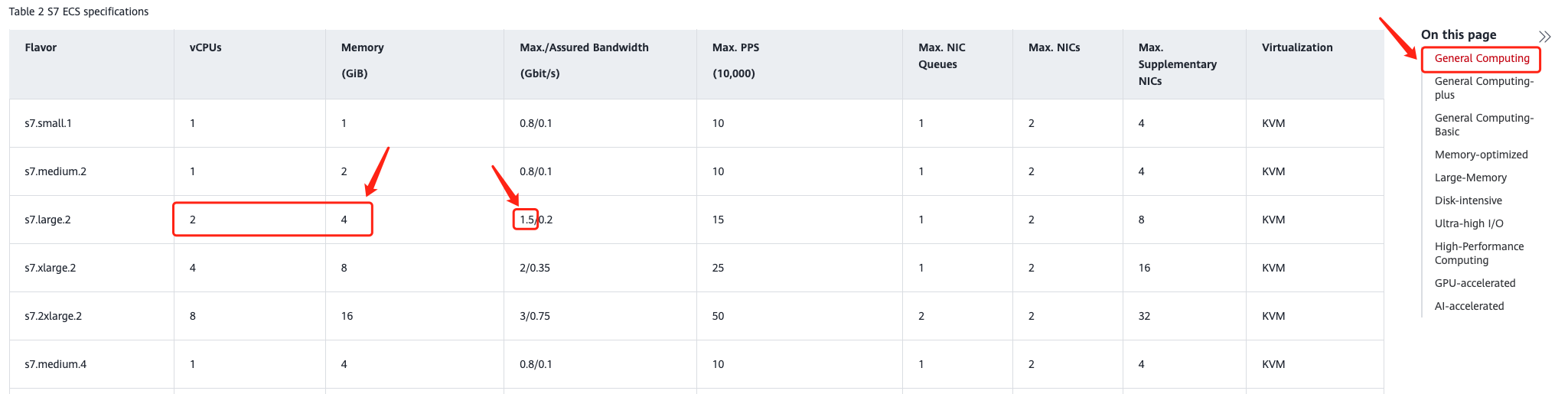
For instance, if the specifications require a memory size of 4GB or less and a maximum bandwidth ranging from 1.5 to 4 Gbps, follow these steps:
Locate each series that meets these requirements. Then, search the Max./Assured Bandwidth (Gbit/s) column in the specifications list for each series, filtering the range between 1.5 and 4 Gbps.
Refine the search by filtering the Memory (GiB) column to find specifications with 4GB or less.
Example Reference: In the General Computing S7 series, under the S7 type, the s7.large.2(2C4G) specification meets the criteria, with 4GB of memory and a maximum bandwidth of 1.5 Gbps.
FAQ
How to test the bandwidth and latency between a local host and a Huawei Cloud host?
How to test latency using the ping command:
Open the command prompt: On the local host, press the Win + R key combination, type cmd, and press Enter.
Run the ping command: In the command prompt, enter the following command, replacing CloudServerIP with the actual IP address of your Huawei Cloud host.
ping CloudServerIPThis will display the round-trip latency between the local host and the Huawei Cloud host.
Performing bandwidth tests using iperf
Install iperf: Install the iperf tool on both the local host and the Huawei Cloud host. You can find relevant installation instructions on the iperf official website(https://iperf.fr/).
Start the iperf server: Run the following command on the Huawei Cloud host:
iperf -s- Run the iperf client: Execute the following command on the local host, replacing CloudServerIP with the actual IP address of your Huawei Cloud host:
iperf -c CloudServerIPThis will display the bandwidth test results from the local host to the Huawei Cloud host.
Client connecting to <Cloud Host IP>, TCP port 5001
TCP window size: 85.3 KByte (default)
------------------------------------------------------------
[ 3] local 192.168.1.2 port 12345 connected with <Cloud Host IP> port 5001
[ ID] Interval Transfer Bandwidth
[ 3] 0.0-10.0 sec 1.10 GBytes 944 Mbits/secTo analyze bandwidth, you only need to look at the "Bandwidth" column. Bandwidth is a measure of network connection speed, usually expressed in bits per second (bps). In the example above, bandwidth is represented in megabits per second (Mbits/sec).
Please note that the results of bandwidth tests may be influenced by network conditions, server performance, and other factors. Before actual application, it is recommended to run multiple tests at different times and under different conditions to obtain more comprehensive bandwidth performance data.