运维指南
运维指南
概览
文档说明
HyperBDR 作为一款云原生的备份与容灾平台,覆盖从 数据保护 到 业务编排 的全流程。运维团队在交付后,需要对系统进行日常的巡检、监控看板的使用、定期容灾演练以及在突发故障时进行快速接管(Failover)。
本手册将为运维人员提供系统的操作指引和最佳实践,确保在生产环境下稳定运行并满足业务连续性需求。
系统架构
架构与说明
系统通过模块化架构实现从生产到目标站点的数据采集、传输、存储与管理,支持容灾、迁移等多种业务场景,具备统一调度与可视化运维能力。
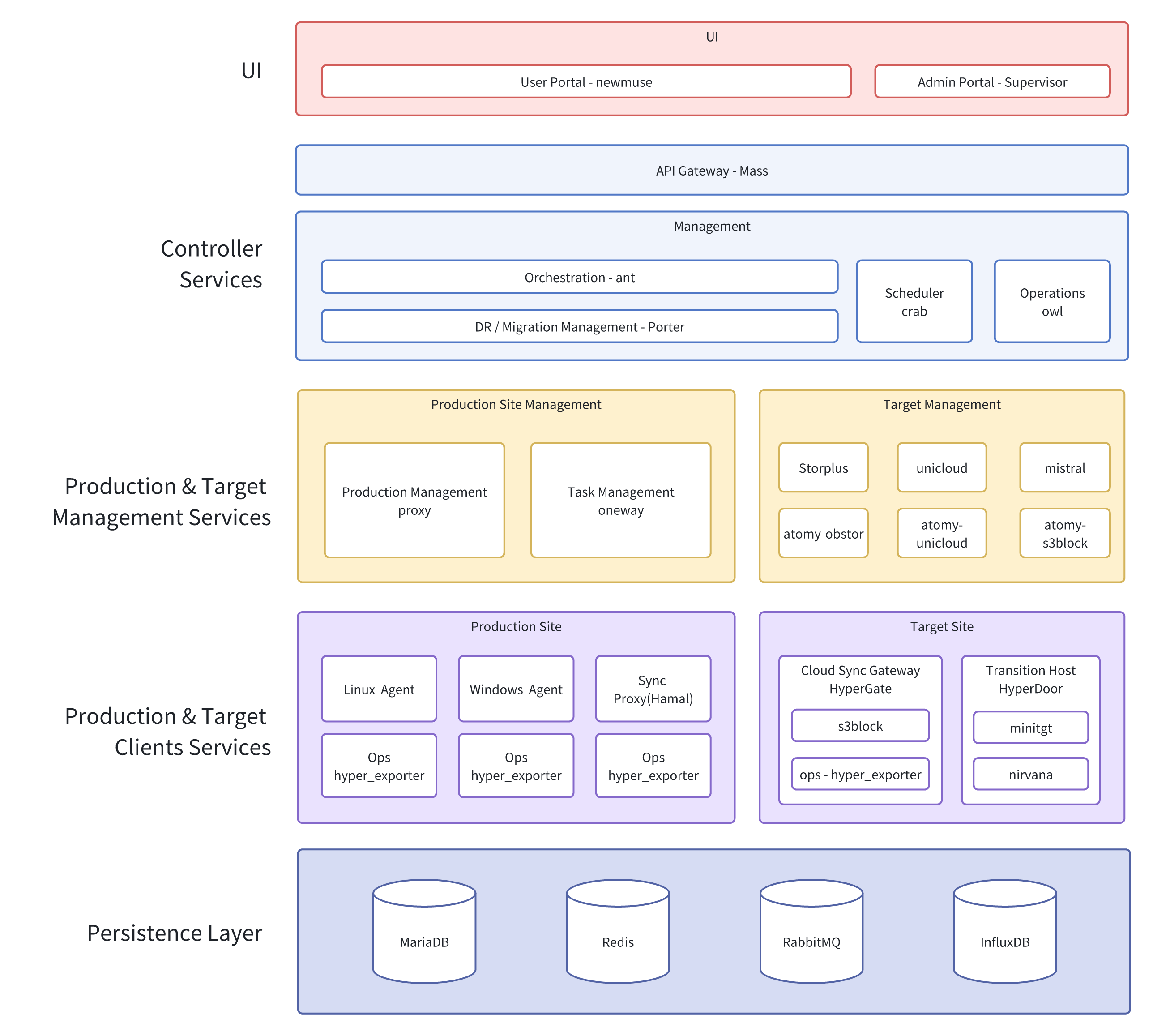
运维管理
日常运维
日常检查
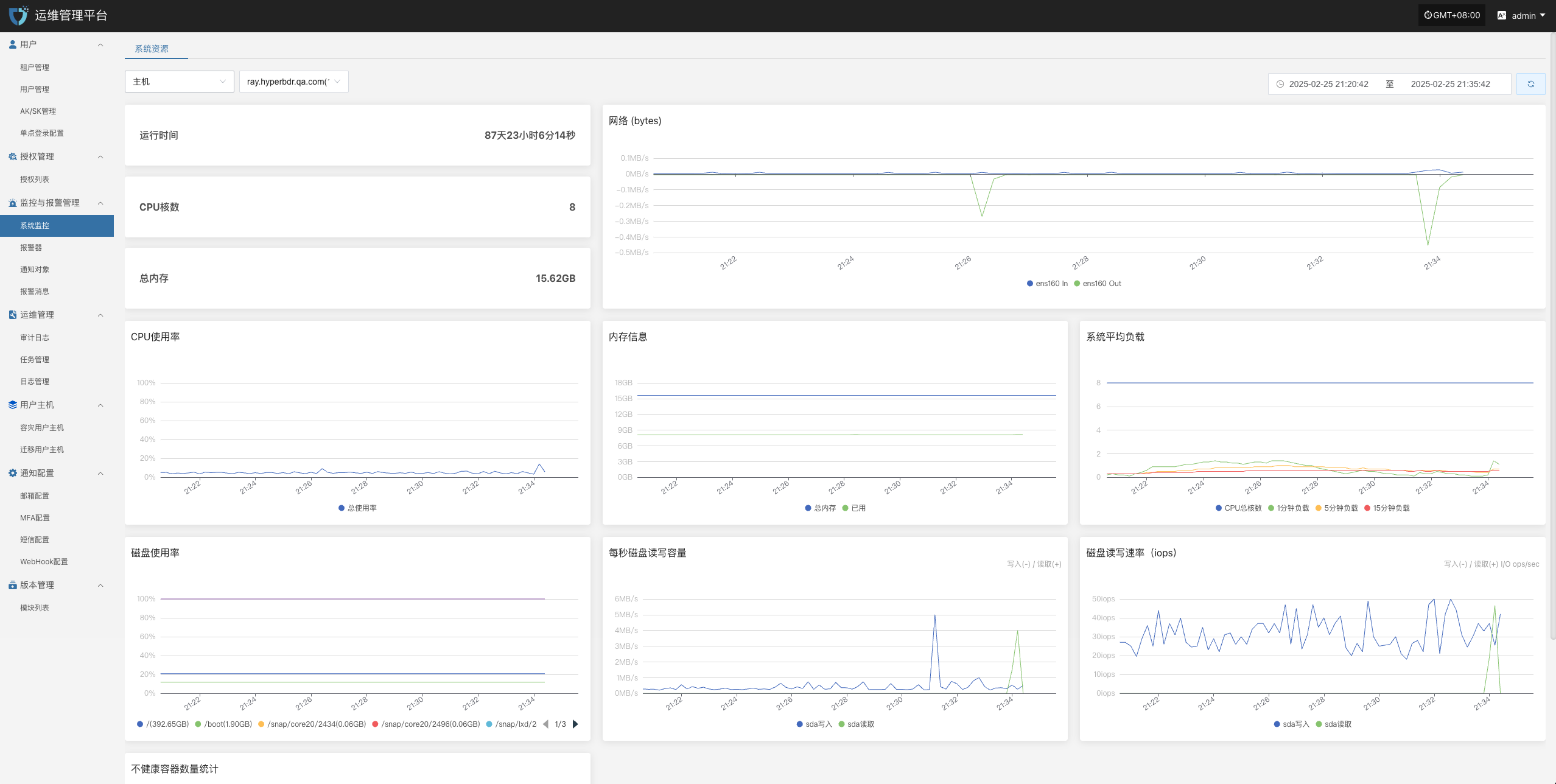
系统健康检查
- 控制台状态:登录 HyperBDR 运维管理平台,检查各个模块的运行状态、CPU/内存/存储等关键资源使用率是否正常。
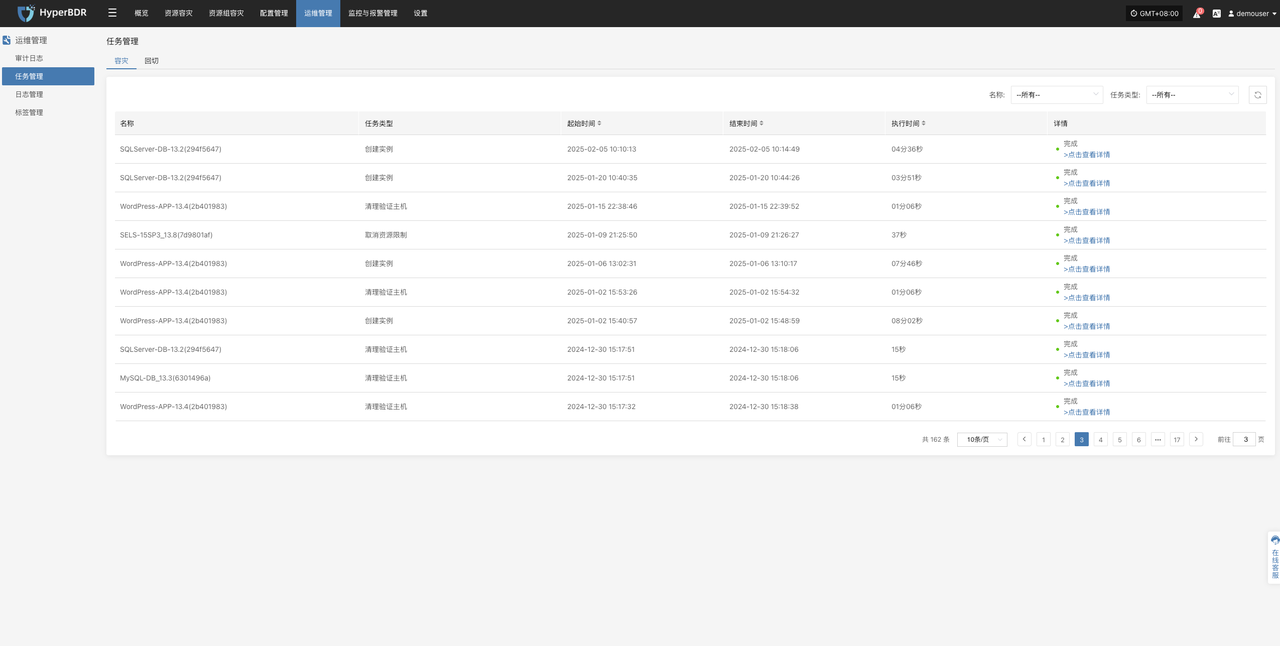
- 备份任务列表:查看所有备份任务执行情况,确认是否有失败或延迟过高的任务。
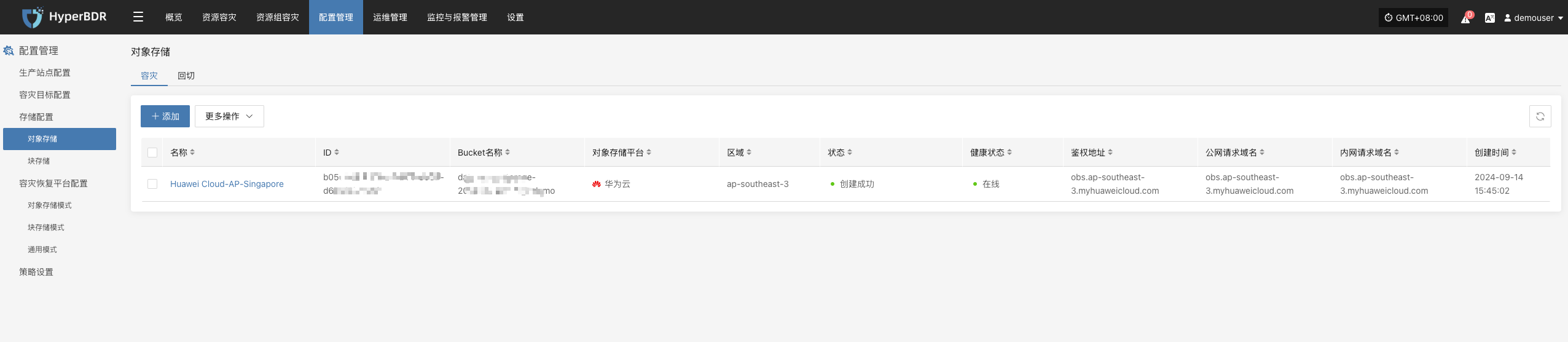
- 日志与告警:通过日志管理模块日志平台检查是否存在异常告警、错误日志。

网络连通性
确保源端(生产环境)与目标端(容灾环境或云平台)之间的网络连接稳定、带宽充足。
若使用 VPN、专线或 VPC Endpoint,需定期检查隧道状态是否正常。
云账户与授权
定期验证云平台账户的有效性、密钥是否过期。
检查账户权限,避免过度授权或缺少关键权限导致备份/恢复失败。
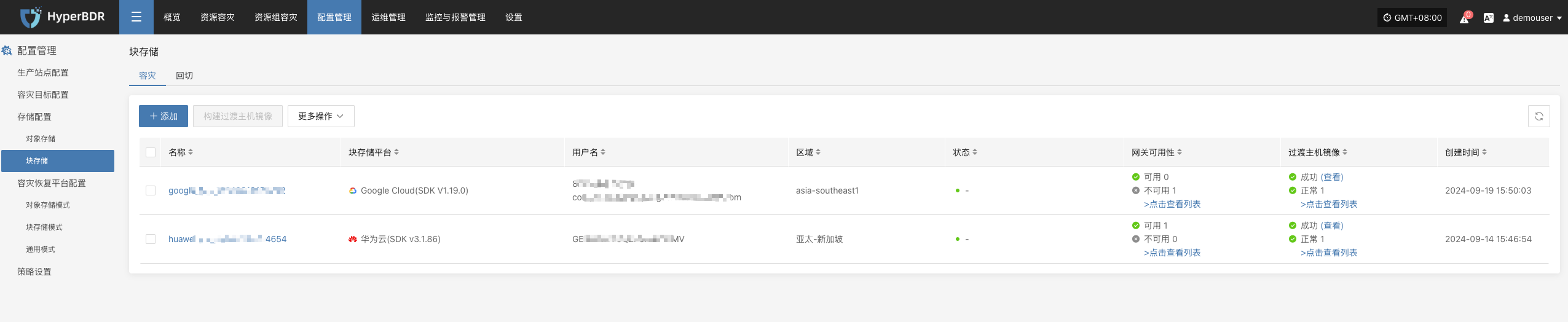
资源监控与备份任务检查
资源监控
- 存储空间:查看对象存储、块存储、数据库存储的剩余容量。若空间不足,需及时扩容或清理历史快照。
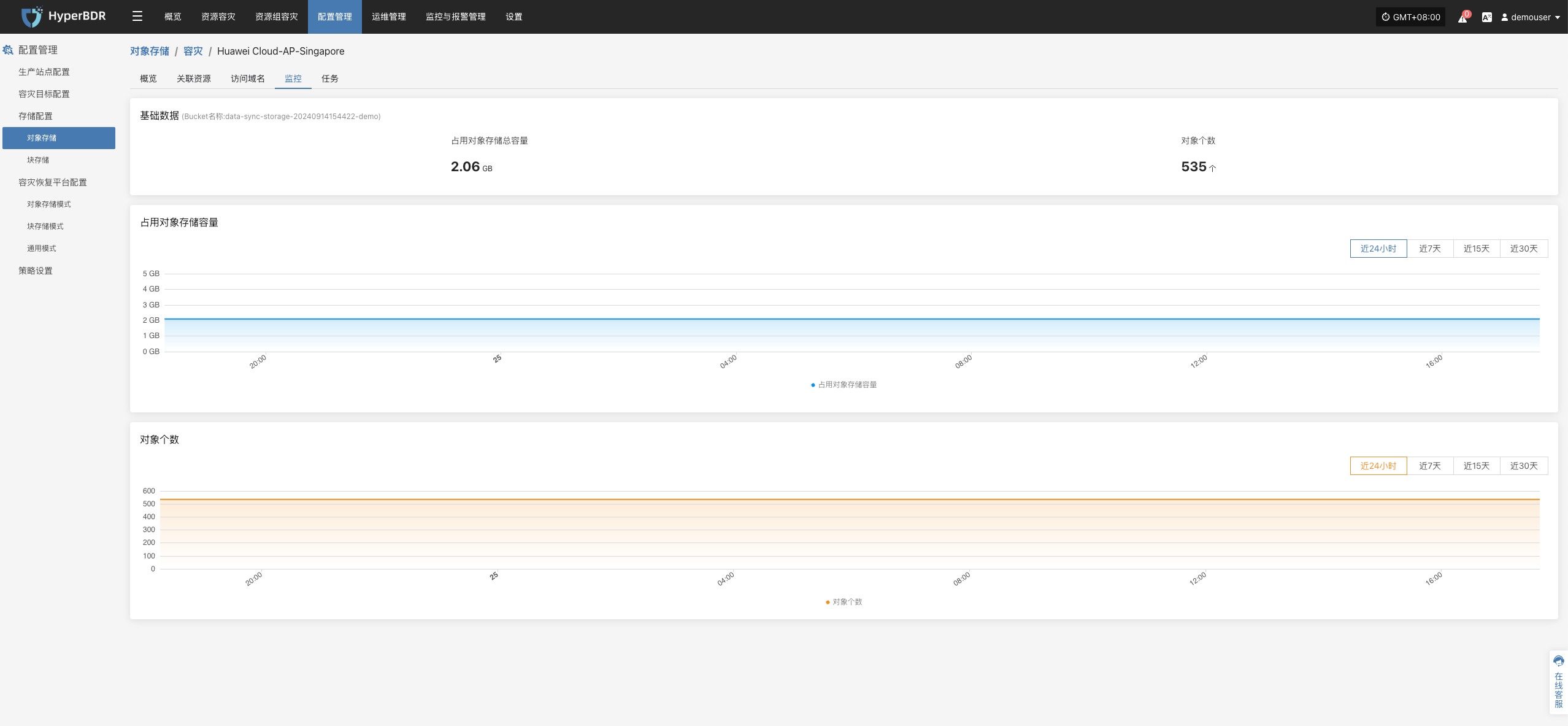
- 网络吞吐量:关注备份高峰期的带宽使用,必要时进行带宽升级或错峰备份策略。
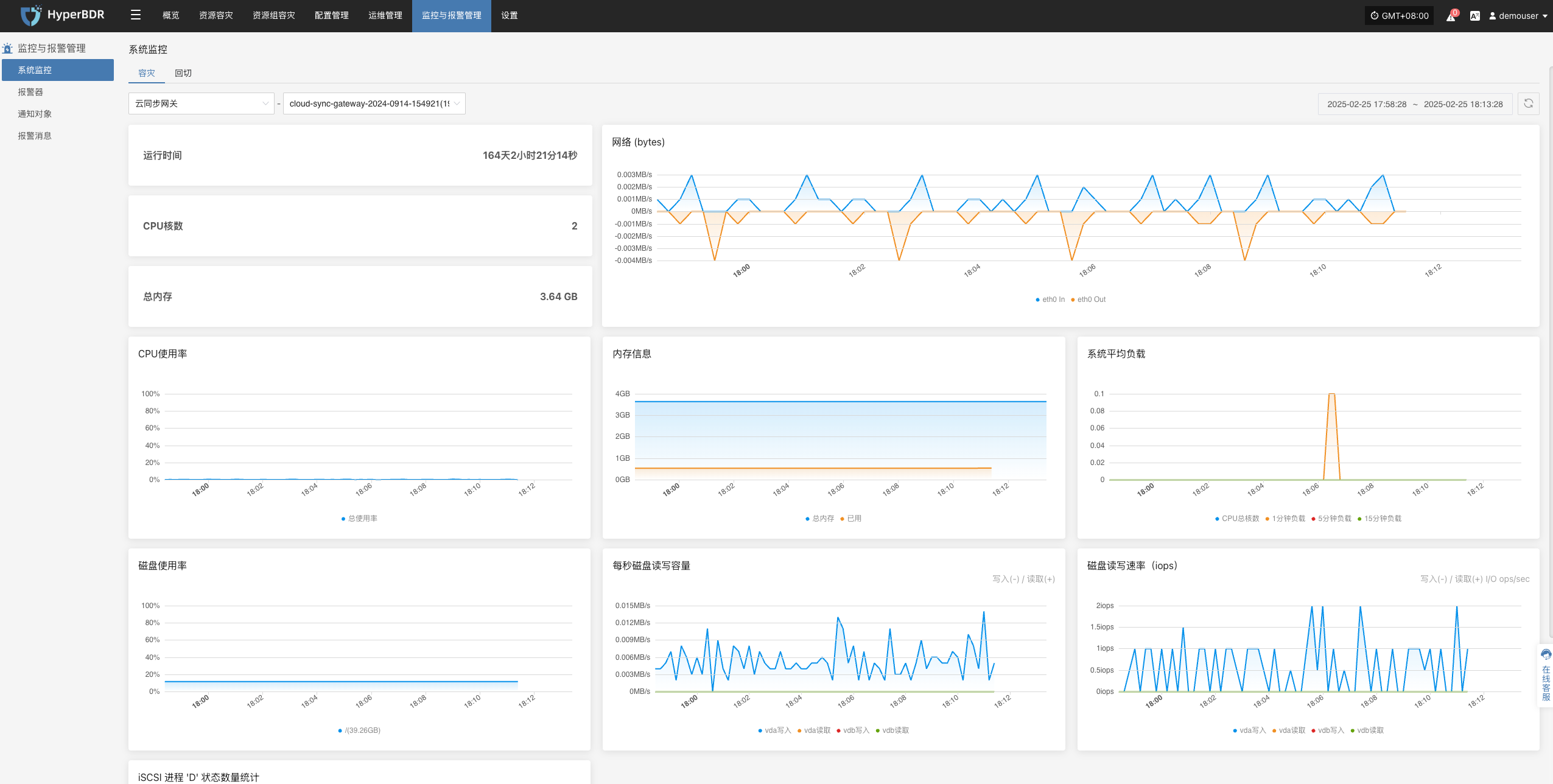
备份任务检查
- 备份策略:每周或每月审查一次备份策略(全量/增量),根据业务变化及时调整备份频率与保留周期。
- 数据一致性校验:定期对备份数据进行校验或抽样恢复测试,确认数据完整可用。
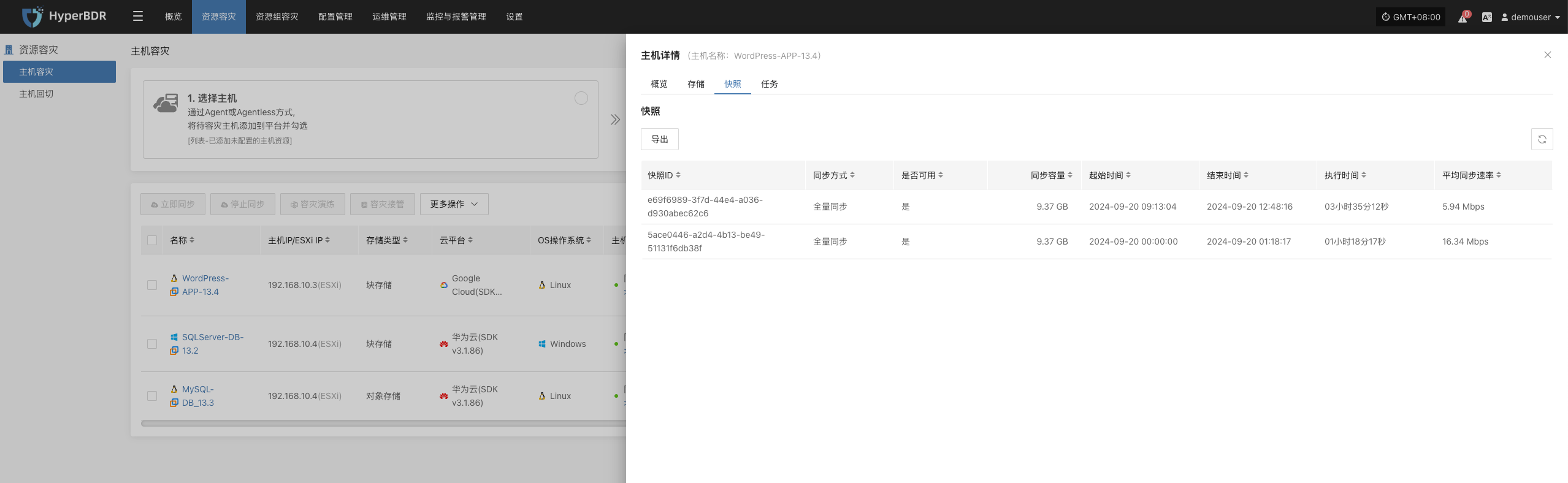
- 异常任务处理:针对备份失败的任务,分析失败原因(网络、权限、存储空间等),及时修复并重新执行。
日志的导出
日志管理功能,可以在出现问题后,第一时间通过日志收集功能,收集服务组件的日志进一步分析定位问题。
控制台
源端同步代理
Linux主机
Windows主机

控制台运维
运行环境说明
控制台是安装在一台Linux主机内(例如:Ubuntu 20.04),控制台所有服务运行在容器内部,数据库及中间件包括MariaDB, Redis, RabbitMQ和InfluxDB。
系统安装在/opt/installer目录中,主要的文件及目录结构:
/opt/installer
├── HyperBDR_release_v6.4.0_20250430-20250430-1079.tar.gz.version # 安装包版本信息
├── Version # 系统整体版本号
├── production/ # 控制台核心运行目录
│ ├── config/ # 各服务配置文件(如 mariadb, redis, proxy 等)
│ ├── data/ # 中间件持久化数据(MySQL, Redis, RabbitMQ, InfluxDB)
│ ├── databackup/ # MySQL、Redis 和配置文件的备份目录
│ ├── docker-compose-hyperbdr.yml # HyperBDR 的容器编排配置
│ ├── docker-compose-hypermotion.yml # HyperMotion 的容器编排配置
│ ├── entrypoint.sh # 系统初始化和启动的入口脚本
│ ├── init/
│ │ └── 01.sql # 数据库初始化 SQL 脚本
│ ├── logs/ # 各服务运行日志(便于排查问题)
│ ├── openssl.cnf # OpenSSL 配置(如证书生成)
│ ├── scripts/ # 安装、升级、卸载、备份等 Shell 脚本
│ ├── softwares/ # 附带的第三方工具包(如 curl、ossutil、ttyd)
│ ├── ttyd # ttyd 可执行程序(Web终端服务)
│ ├── venvs/ # 各服务的 Python 虚拟环境(venv 隔离依赖)
│ └── version # 当前部署版本信息服务健康状态
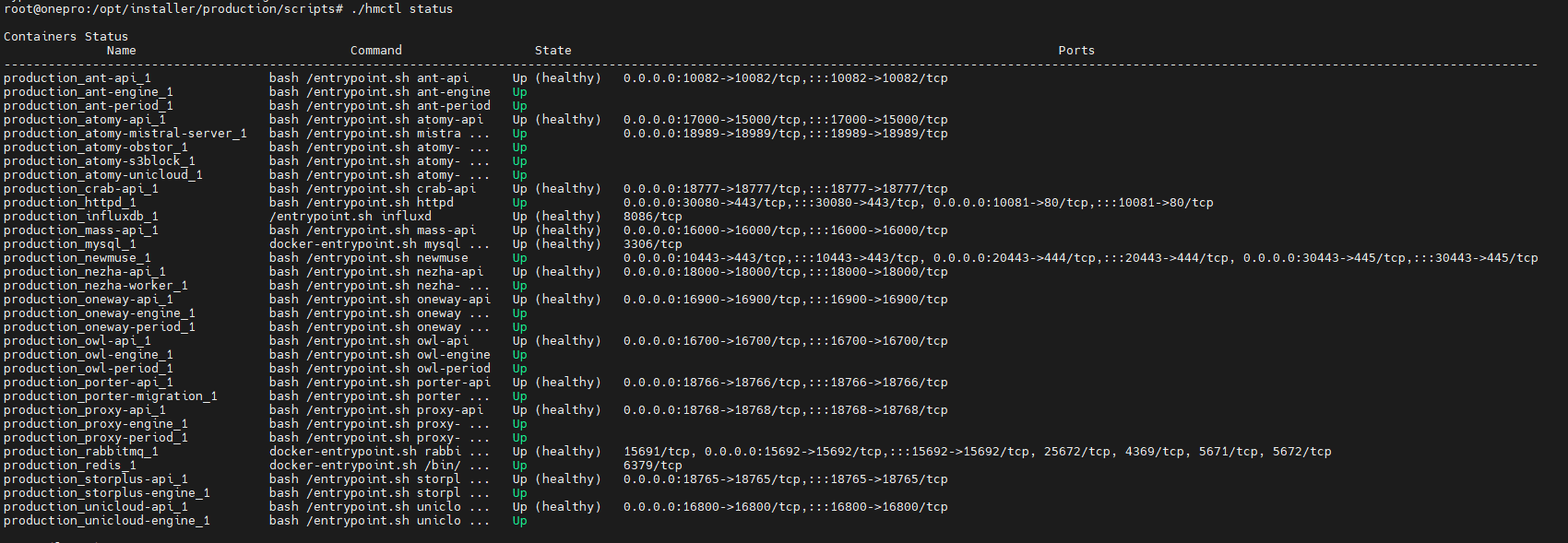
所有服务均以 Docker 容器方式运行,运维人员可通过 hmctl 命令检查服务状态。
返回结果包括:
/opt/installer/production/scripts/hmctl status注意:可为其增加系统环境变量使其全局调用
echo 'export PATH=$PATH:/opt/installer/production/scripts' >> ~/.bashrc
source ~/.bashrc- 当前服务健康状况
关键是看 State 列:
Up:表示服务运行正常
Up (healthy):表示容器正在运行且健康检查通过。
Exit / Restarting:表示服务异常或未能启动
- 日志占用空间

- 程序占用空间

- 磁盘剩余空间

- 10443服务端口健康状况

服务启动/停止/重启
运维人员可通过 hmctl 命令对服务进行启动、停止、重启操作。
注意:如果已经加入全局变量则直接执行:hmctl <命令参数>
启动服务
- 启动全部服务
/opt/installer/production/scripts/hmctl start- 启动单个服务
/opt/installer/production/scripts/hmctl start <服务名>停止服务
- 停止全部服务
/opt/installer/production/scripts/hmctl stop- 停止单个服务
/opt/installer/production/scripts/hmctl stop <服务名>重启服务
- 重启全部服务
/opt/installer/production/scripts/hmctl restart- 重启单个服务
/opt/installer/production/scripts/hmctl restart <服务名>重新加载服务
注意:该命令只用于基础镜像有更新的情况下使用
/opt/installer/production/scripts/hmctl reload
日志管理
所有系统后台日志统一存放在 /var/log/installer 目录中,运维人员可直接访问这些日志来监控系统运行状态、排查故障,或将相关文件提供给项目负责人,确保系统稳定性。
/var/log/installer/
├── autoinstall-user-data # 自动安装用户数据配置文件
├── block # 存放与磁盘块相关的数据,通常用于分区信息
├── casper-md5check.json # 用于验证安装镜像的MD5值,确保镜像文件完整性
├── curtin-install-cfg.yaml # Curtin安装工具的配置文件,控制安装过程
├── curtin-install.log # Curtin安装过程的日志文件,记录安装的详细步骤和错误
├── installer-journal.txt # 安装过程中的重要事件日志
├── media-info # 安装介质的信息文件,通常包括介质类型等
├── subiquity-client-debug.log -> subiquity-client-debug.log.2396 # Subiquity客户端调试日志的符号链接,指向日志文件 .2396
├── subiquity-client-debug.log.2396 # Subiquity客户端调试日志文件
├── subiquity-client-info.log -> subiquity-client-info.log.2396 # Subiquity客户端详细日志的符号链接,指向日志文件 .2396
├── subiquity-client-info.log.2396 # Subiquity客户端的详细日志文件
├── subiquity-curtin-apt.conf # Curtin安装过程中APT包管理器的配置文件
├── subiquity-curtin-install.conf # Curtin安装过程的具体配置文件
├── subiquity-server-debug.log -> subiquity-server-debug.log.2463 # Subiquity服务器端调试日志的符号链接,指向日志文件 .2463
├── subiquity-server-debug.log.2463 # Subiquity服务器端调试日志文件
├── subiquity-server-info.log -> subiquity-server-info.log.2463 # Subiquity服务器端详细日志的符号链接,指向日志文件 .2463
└── subiquity-server-info.log.2463 # Subiquity服务器端的详细日志文件日志采集
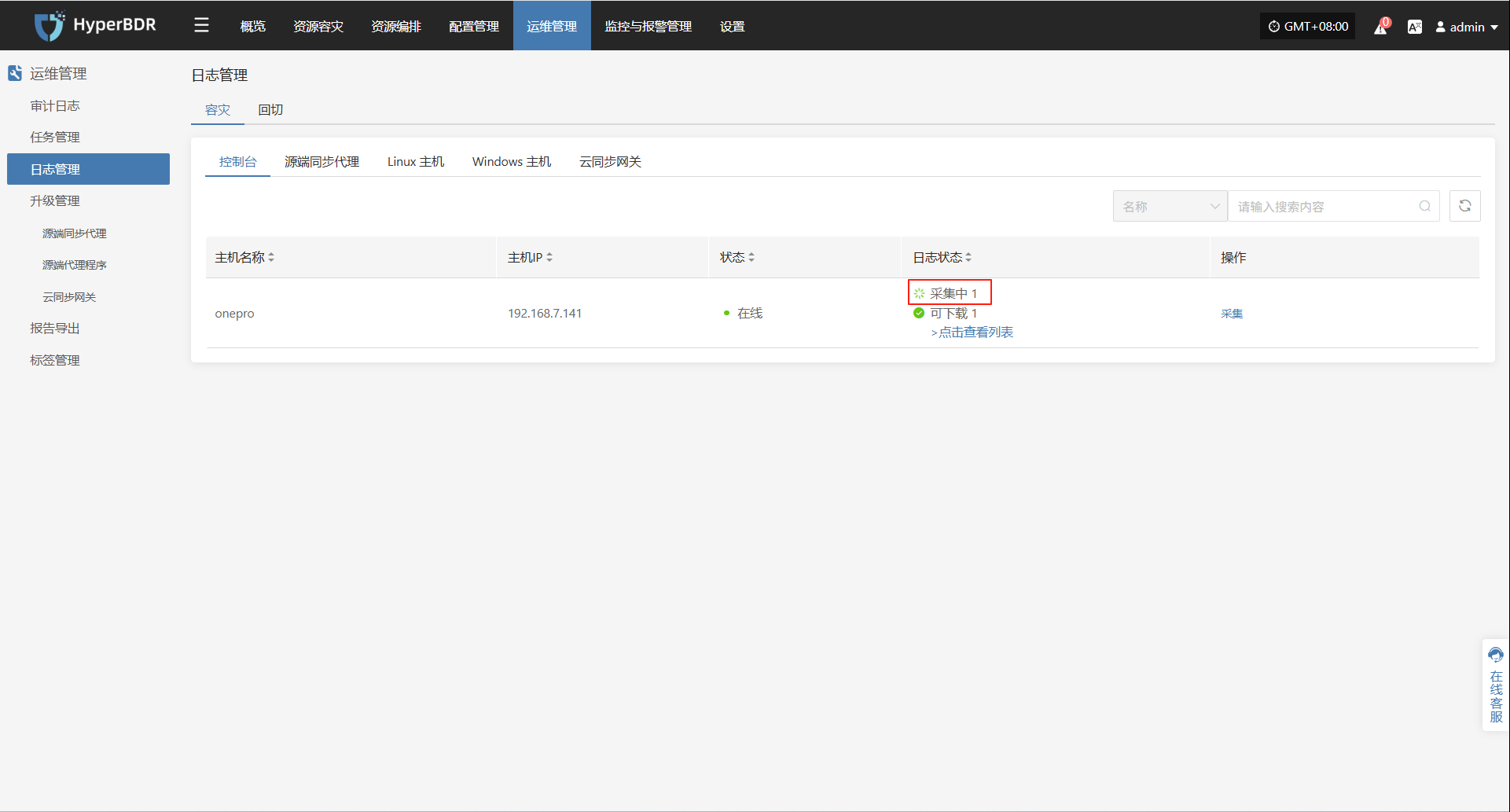
在 HyperBDR 系统中,运维人员可通过在"运维管理 > 日志管理 > 容灾|回切 > 控制台"页面,根据实际需求,收集与下载所需日志文件,便于问题排查与系统监控。
选择需要收集的目标主机,点击对应行的“采集”操作按钮
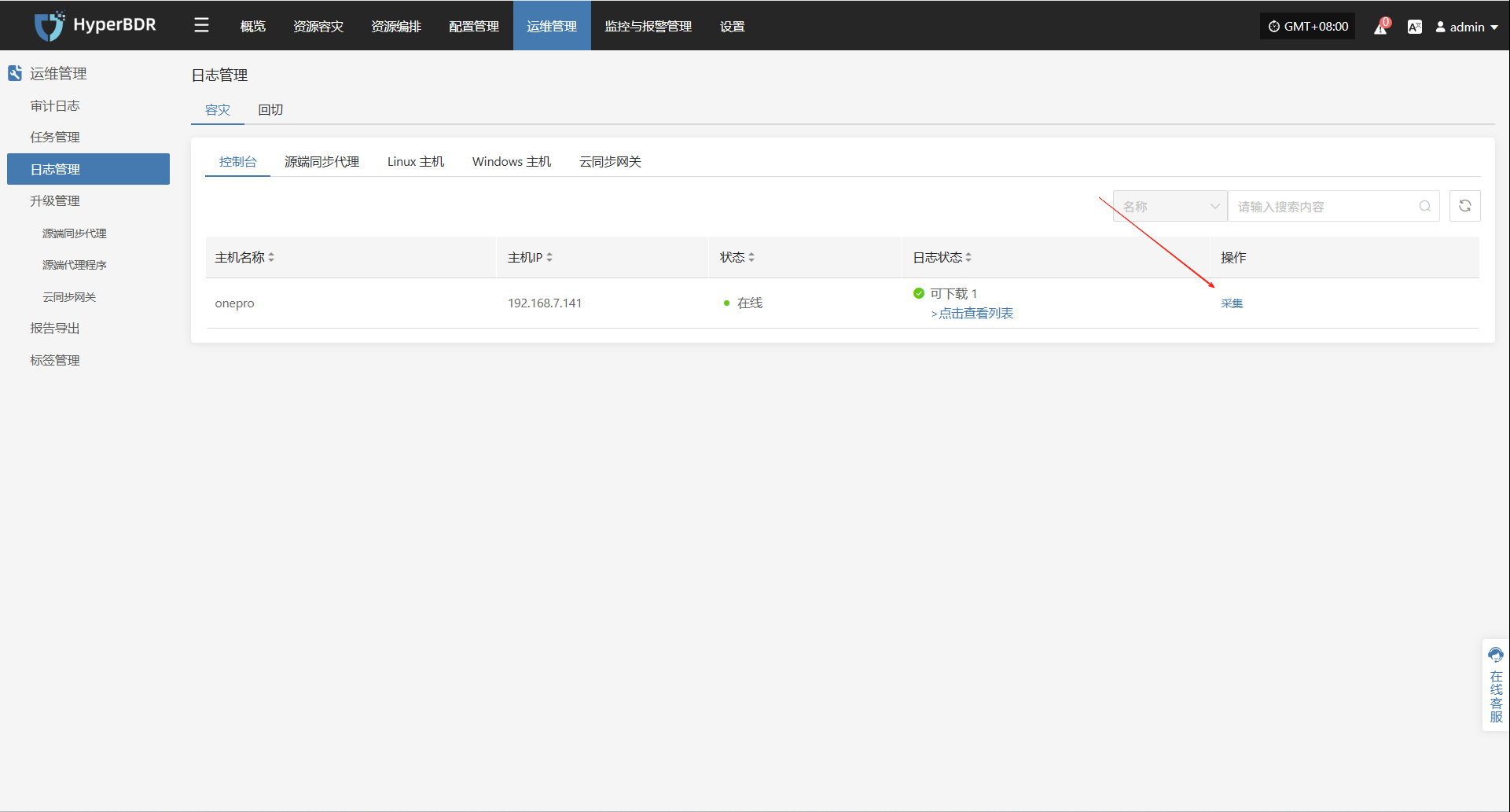
选择时间段
在弹出的对话框中设定需要收集的日志时间范围,确认后系统将自动开始日志收集
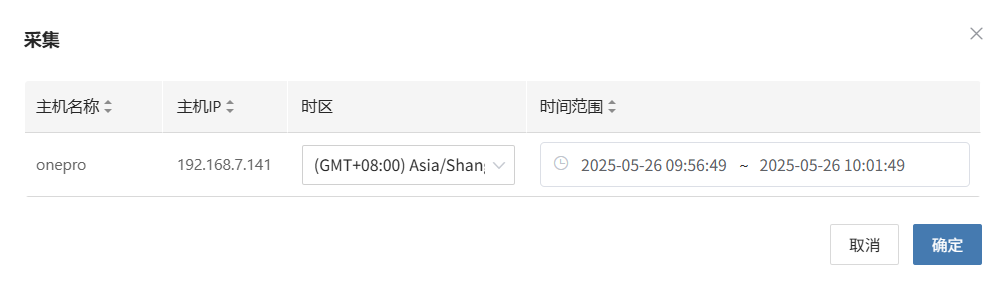
开始采集
选择时间段确认后,系统将自动开始日志收集,日志状态转换为采集中
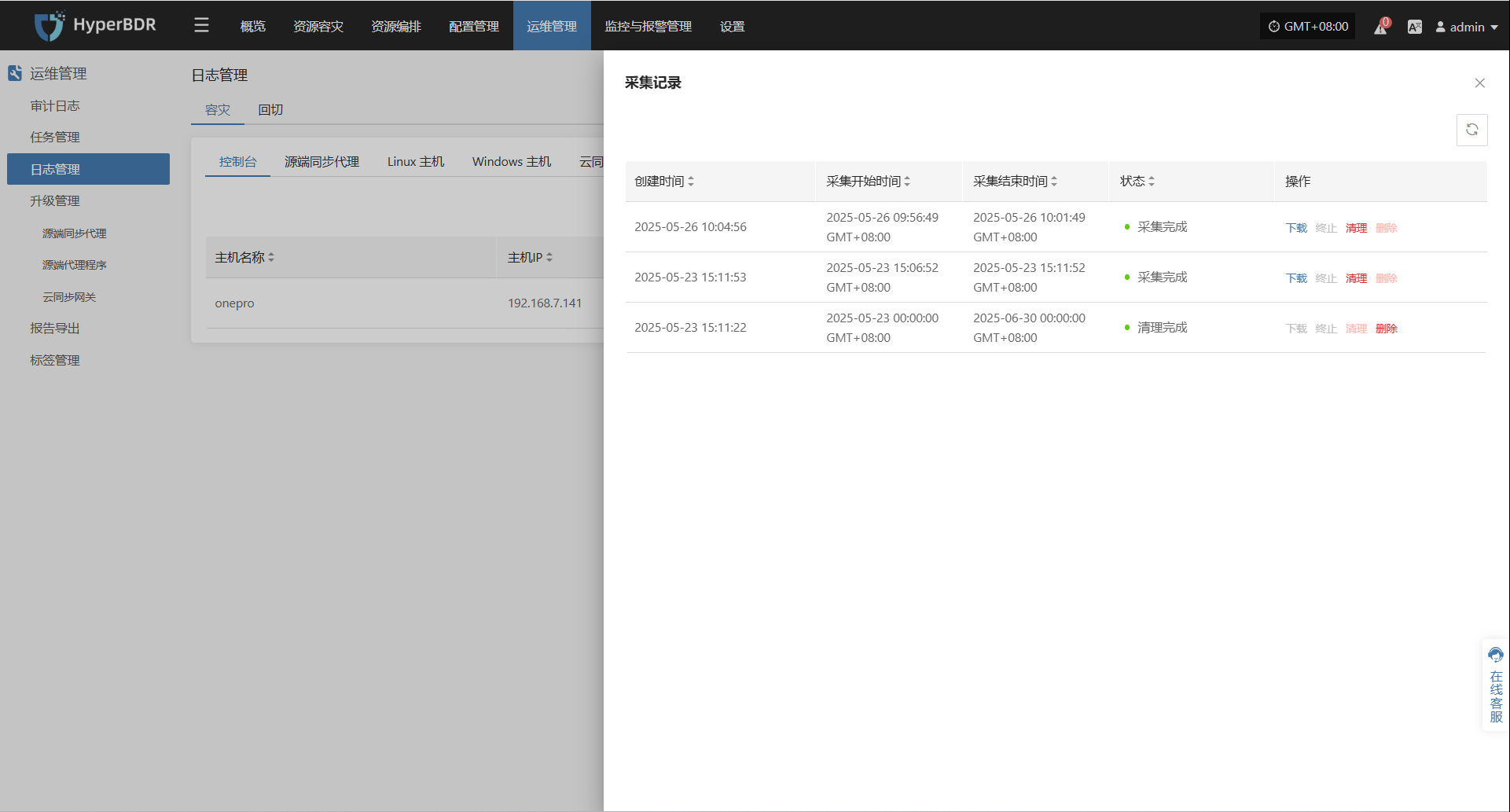
日志下载
日志采集完成后,状态更新为“可下载”,用户可点击“点击查看列表”查看日志文件,并选择下载
配置文件管理
系统的所有配置文件存储在 /opt/installer/production/config 目录中。运维人员可根据需求修改配置文件,以调整系统行为和功能设置。
由于配置文件繁多此处不一一列举
下列为ant服务配置文件实例:
[DEFAULT]
### 调试和日志
debug = False # 是否开启调试模式
verbose = False # 是否启用详细日志
ant_api_listen = 0.0.0.0 # API监听地址
ant_api_listen_port = 10082 # API监听端口
transport_url = rabbit://guest:fs82BgKdU2QTr4Oy@rabbitmq:5672// # RabbitMQ连接URL
### 日志轮转设置(已注释,按需启用)
### log_rotation_type = size # 设置日志轮转方式(可选:size, time)
### max_logfile_count = 10 # 最大日志文件数量
### max_logfile_size_mb = 64 # 最大日志文件大小(MB)
### API服务设置
ant_api_workers = 1 # 启动的API工作线程数
proxy_base_url = http://proxy-api:18768 # 代理服务的基本URL
porter_base_url = http://porter-api:18766 # Porter服务的基本URL
porter_proxys_url = http://porter-api:18766/proxys # Porter代理接口URL
storplus_base_url = http://storplus-api:18765 # Storplus服务的基本URL
OWL_BASE_URL = "http://owl-api:16700" # OWL服务的基本URL
[database]
### 数据库连接配置
backend = sqlalchemy # 使用的ORM后端(如:sqlalchemy)
connection = mysql://ant:antPass@mysql:3306/ant?charset=utf8 # MySQL数据库连接字符串
use_db_reconnect = True # 是否启用数据库自动重连
max_pool_size = 30 # 数据库连接池最大连接数
max_overflow = 20 # 数据库连接池的最大溢出连接数
pool_timeout = 30 # 获取数据库连接的超时时间(秒)
connection_recycle_time = 300 # 连接重用时间(秒),超过此时间后连接会被关闭并重新创建
[period]
### 定时任务相关配置
interval = 5 # 定时任务的执行间隔(秒)
timeout = 86400 # 定时任务的超时时间(秒),默认一天(86400秒)源端同步代理(Sync Proxy)
运行环境说明
在源端主机安装代理程序,直接通过云平台的 API 接口或虚拟化平台的管理接口(如 VMware vCenter)捕获数据变化,实现无侵入的数据同步,适用于虚拟化环境,简化部署并降低系统资源占用。
Linux Agentless 部署在 Ubuntu 24.04 主机上,推荐配置为 4 核 CPU、8GB 内存、50GB 硬盘,使用 ext4 或 xfs 文件系统(不支持 LVM 分区)。
系统安装在/opt/hamal目录中,主要的文件及目录结构:
/opt/hamal
├── docker-compose-hamal.yaml # Docker Compose 配置文件,用于部署 Hamal 服务
├── hamal-venv # Python 源码包
│ ├── bin # Python 的可执行文件
│ ├── etc # 配置文件目录
│ ├── hamal3-changelog.txt # Hamal 版本更新日志
│ ├── include # 包含目录(通常是 C 库等)
│ ├── lib # Python 库文件
│ ├── project_etc # 项目专用的配置文件
│ ├── pyvenv.cfg # Python 虚拟环境配置文件
│ ├── tools # 工具集文件目录
│ └── version # 版本文件,标记当前虚拟环境版本
├── uninstall_hamal.sh # 卸载 Hamal 服务的脚本
└── update_sync_proxy.sh # 更新同步代理的脚本服务健康状态
Agentless 服务以 Docker 容器方式运行,运维人员可通过以下命令检查服务状态:
cd /opt/hamal
docker-compose -f docker-compose-hamal.yaml ps执行后将显示服务的运行状态信息,如下所示:
关键是看 State 列:
Up:表示服务运行正常
Up (healthy):表示容器正在运行且健康检查通过。
Exit / Restarting:表示服务异常或未能启动

服务启动/停止/重启
运维人员可以使用 docker-compose 管理 Agentless 服务的启动、停止和重启操作
启动服务:
docker-compose -f /opt/hamal/docker-compose-hamal.yaml up -d停止服务:
docker-compose -f /opt/hamal/docker-compose-hamal.yaml down重启服务:
docker-compose -f /opt/hamal/docker-compose-hamal.yaml restart
日志管理
所有系统日志文件存储在/var/log/hamal目录中。运维人员可以通过查看,日志文件,监控系统运行状态,排查故障,或提供相关文件给到对应项目负责人,确保系统稳定性。
/var/log/hamal
├── hamal-period.log # Hamal 定时任务的主日志(约 188KB)
├── hamal-period-subprocess.log # Hamal 定时任务中子进程的日志(约 10KB)
├── ip_mapping.backup # IP 映射的备份文件(当前为空)
├── vm-kylin_v10_Agent-<UUID>.log # 虚拟机代理相关,可以通过vm开头的日志,来判断是否同步状态日志采集
在 HyperBDR 系统中,运维人员可通过在"运维管理 > 日志管理 > 容灾|回切 > 源端同步代理"页面,根据实际需求,收集与下载所需日志文件,便于问题排查与系统监控。
选择需要收集的目标主机,点击对应行的“采集”操作按钮
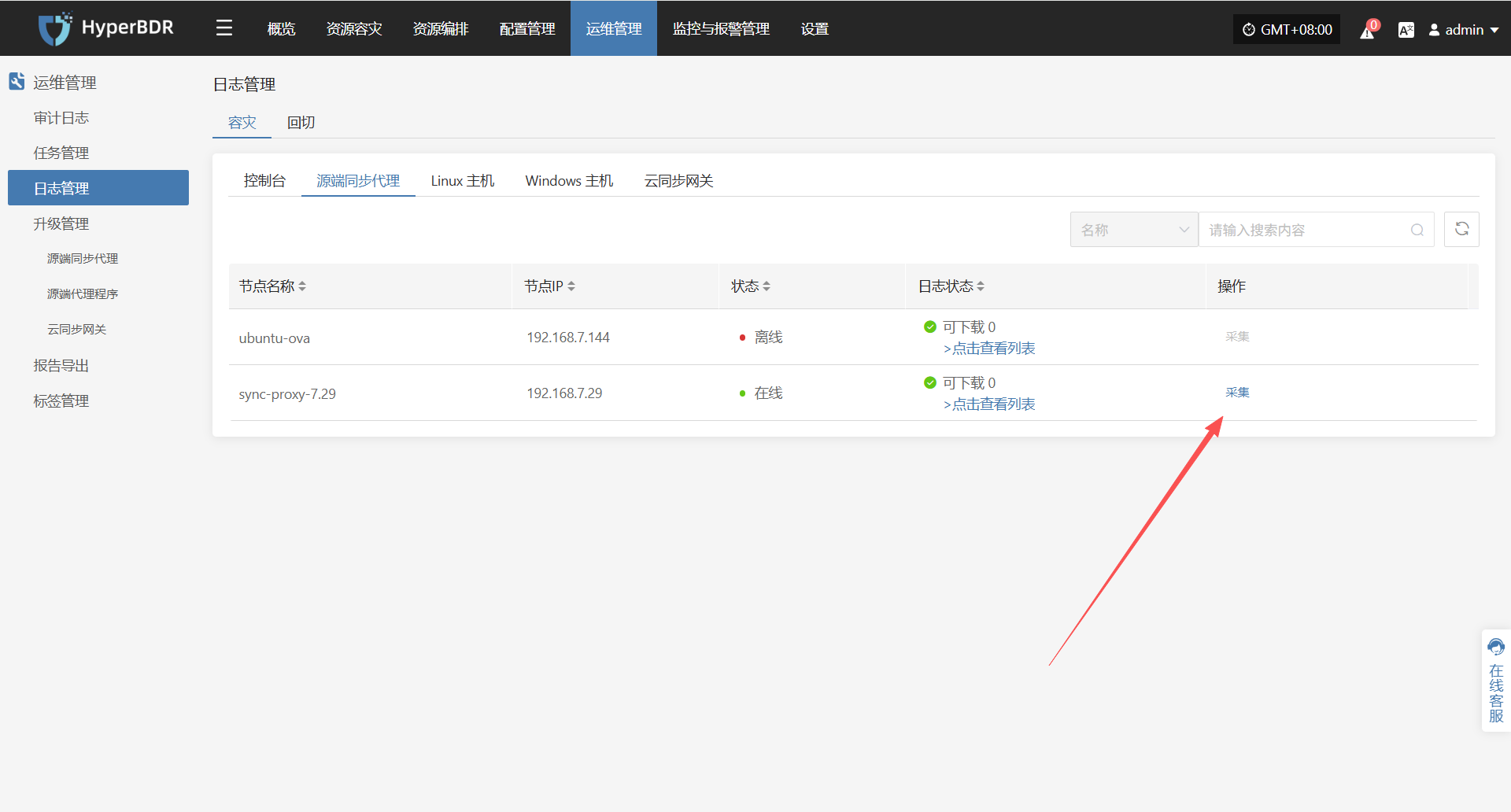
选择时间段
在弹出的对话框中设定需要收集的日志时间范围,确认后系统将自动开始日志收集
开始采集
选择时间段确认后,系统将自动开始日志收集,日志状态转换为采集中
日志下载
日志采集完成后,状态更新为“可下载”,用户可点击“点击查看列表”查看日志文件,并选择下载
配置文件管理
Linux Agent 的主要配置文件位于 /etc/hamal 目录下,文件名为 hamal.conf 。该文件包含了 Agentless 的各项配置信息,包括服务连接、数据库、同步任务、日志、S3 配置等。
以下是该配置文件的各个部分及其作用说明:
[DEFAULT]
debug = False # 是否启用调试日志
verbose = False # 是否启用详细日志
log_rotation_type = size # 日志轮转方式:按大小轮转
max_logfile_count = 10 # 最大日志文件数量
max_logfile_size_mb = 64 # 单个日志文件最大大小(单位:MB)
hamal_lib_dir = /var/lib/hamal/ # 程序数据目录
hamal_info_path = /var/lib/hamal/hamal_info # 程序信息文件路径
[period]
interval = 60 # 执行周期任务的间隔(单位:秒)
task_update_wait_time = 1 # 任务更新时间等待间隔(单位:秒)
openstack_release_cpu_time = 0 # OpenStack 每 MB 数据释放占用 CPU 时间(单位:毫秒)
vmware_release_cpu_time = 0 # VMware 每 MB 数据释放占用 CPU 时间(单位:毫秒)
[mass]
mass_endpoint = https://192.168.7.141:10443/hypermotion/v1 # Mass 服务 API 地址
auth_key = 315d65ca-ef28-4e63-ad72-1260a91adf23 # 鉴权使用的密钥
hyper_exporter_id = aaeb0d1fbbb14093837fb5f900b9f8ce # Hyper Exporter 的唯一 ID
public_key_path = /etc/hamal/public_key # 公钥路径
default_request_timeout = 600 # 请求超时时间(单位:秒)
enable_get_public_ips = False # 是否获取公网 IP
get_public_ip_timeout = 5 # 获取公网 IP 的超时时间(单位:秒)
enable_heartbeat_msg = True # 是否启用心跳上报
[vmware]
skip_disk_flag = False # 是否跳过磁盘标识检查
disk_flag_size = 48 # 标识磁盘的最小容量(单位:MB)
max_read_blocks = 1024 # 单次读取的最大块数
[openstack_ceph]
skip_disk_flag = False # 是否跳过磁盘标识检查
disk_flag_size = 48 # 标识磁盘的最小容量(单位:MB)
[sync]
save_local_snapshot_metadata = False # 是否本地保存快照元数据
upload_metadata_to_oss = False # 是否上传元数据到 OSS
[data_sync_v2]
fsync_period_frequency = 3 # 元数据周期同步频率(单位:秒)
fsync_timeout = 0 # 同步超时时间(单位:秒)
parallel_sync_disks_count = 4 # 并行同步磁盘数量
pre_disk_readers_count = 2 # 预处理磁盘读取线程数
max_parallel_sync_disks_count = 16 # 最大并行磁盘同步数量
max_pre_disk_readers_count = 16 # 最大预处理磁盘读取线程数
[fusion_compute]
task_timeout = 3600 # 任务超时时间(单位:秒)
create_snap_task_timeout = 3600 # 创建快照超时时间(单位:秒)
delete_snap_task_timeout = 3600 # 删除快照超时时间(单位:秒)
local_host_ip = "" # 当前主机 IP(可选)
max_socket_connections_per_host = 8 # 单主机最大连接数
max_writer_num = 10 # 最大写入线程数Linux Agent运维
运行环境说明
通过在源端服务器上部署 Agent 程序,实时捕获文件系统或块设备的变化,实现对数据的持续同步,适用于物理服务器、非虚拟化环境或需要更精细控制的场景。
Linux Agent 支持部署在以下版本的 Linux 操作系统上:CentOS 6.5+、CentOS 7.x/8.x、RHEL 6.x/7.x/8.x、SLES 11 SP1/SP3/SP4,以及 Ubuntu Server 12.04/14.04/16.04/18.04/20.04(均为 64 位)。
系统安装在/var/lib/egisplus-agent目录中,主要的文件及目录结构:
egisplus-agent/
├── agent-sync.db # 本地同步数据库,存储代理同步状态
├── agent-sync.db-shm # SQLite 共享内存文件
├── agent-sync.db-wal # SQLite 写前日志文件
├── collect_system_info.sh # 采集系统信息的脚本
├── config.ini # 主配置文件(如服务地址、认证信息等)
├── disk_uuid_map # 磁盘 UUID 与设备路径映射
├── egisplus-agent # 主执行程序(代理核心)
├── egisplus_version # Agent 的版本信息
├── fstab.bak # `/etc/fstab` 文件备份(挂载点信息)
├── hw_serial # 主机硬件序列号(用于唯一标识)
├── protect_type # 保护类型定义(如全量、增量)
├── public_key # 与服务端通信使用的公钥
├── registered # 是否注册标记(通常空文件表示已注册)
├── uninstall_agent.sh # 卸载脚本,清理安装和配置
├── upgrade_agent.sh # 升级脚本,用于更新 agent 版本
└── version # 版本号文件,标识当前运行版本服务健康状态
Linux Agent 安装完成后,通过 egisplus-cli 工具进行运行和管理。运维人员可使用相关命令检查服务状态与执行控制操作。
命令结构说明:
egisplus-cli agent <子命令>
子命令 说明
check 检查代理状态,可能是健康检查或运行状况检查
clean 清理某些缓存或临时数据
cow 可能是 Copy-On-Write 相关操作
devices 显示或管理设备(磁盘、分区等
fs 文件系统相关操作(如挂载、检测
log 查看代理相关的日志
read_rate 查看或配置读取速率限制
version 显示 `egisplus-cli` 工具的版本信息下列示例为执行一次代理状态检查:
egisplus-cli agent check返回的是 egisplus-cli 程序的运行状态检查结果:
Service status
Agent service is started: Yes. ##Agent 服务正在运行
iSCSI service is started: Yes. ##iSCSI 服务也已启动,说明该节点可能用于块级存储或备份挂载
Agent status
This agent is registered: Yes. ##表示这个代理已经成功注册到HyperBDR
This agent is protected : No. ##这里的no表示还没有开始同步数据
Heartbeat of this agent : 305. ##表示代理与控制端有心跳连接,数值显示连接正常
File system
block mount fs free used path
/dev/dm-0 / xfs 185G 4% /dev/mapper/centos-root ##这部分显示了当前系统的挂载磁盘和使用情况
/dev/sda1 /boot xfs 853M 16% /dev/sda1 ##这部分显示了当前系统的挂载磁盘和使用情况服务启动/停止/重启
运维人员可通过systemd用以下命令对 egisplus-agent.service 进行管理:
启动服务
systemctl start egisplus-agent.service停止服务
systemctl stop egisplus-agent.service重启服务
systemctl restart egisplus-agent.service
日志管理
所有系统日志文件存储在 /var/log/egisplus-agent 目录中。运维人员可以通过查看,日志文件,监控系统运行状态,排查故障,或提供相关文件给到对应项目负责人,确保系统稳定性。
egisplus-agent/
├── agent-syncer.log # 与控制中心/云端同步任务的运行日志
├── agent-syncer-panic.log # 同步任务的异常/崩溃日志,问题排查首选
├── db.log # 与本地状态数据库或元数据相关的操作日志
├── linux_agent.log # 主代理程序的核心运行日志,记录服务启动、注册、调度等
└── linux_agent.log-20250511.gz # 自动轮转的归档历史日志,gzip 压缩格式日志采集
在 HyperBDR 系统中,运维人员可通过在"运维管理 > 日志管理 > 容灾|回切 > Linux主机"页面,根据实际需求,收集与下载所需日志文件,便于问题排查与系统监控。
选择需要收集的目标主机,点击对应行的“采集”操作按钮
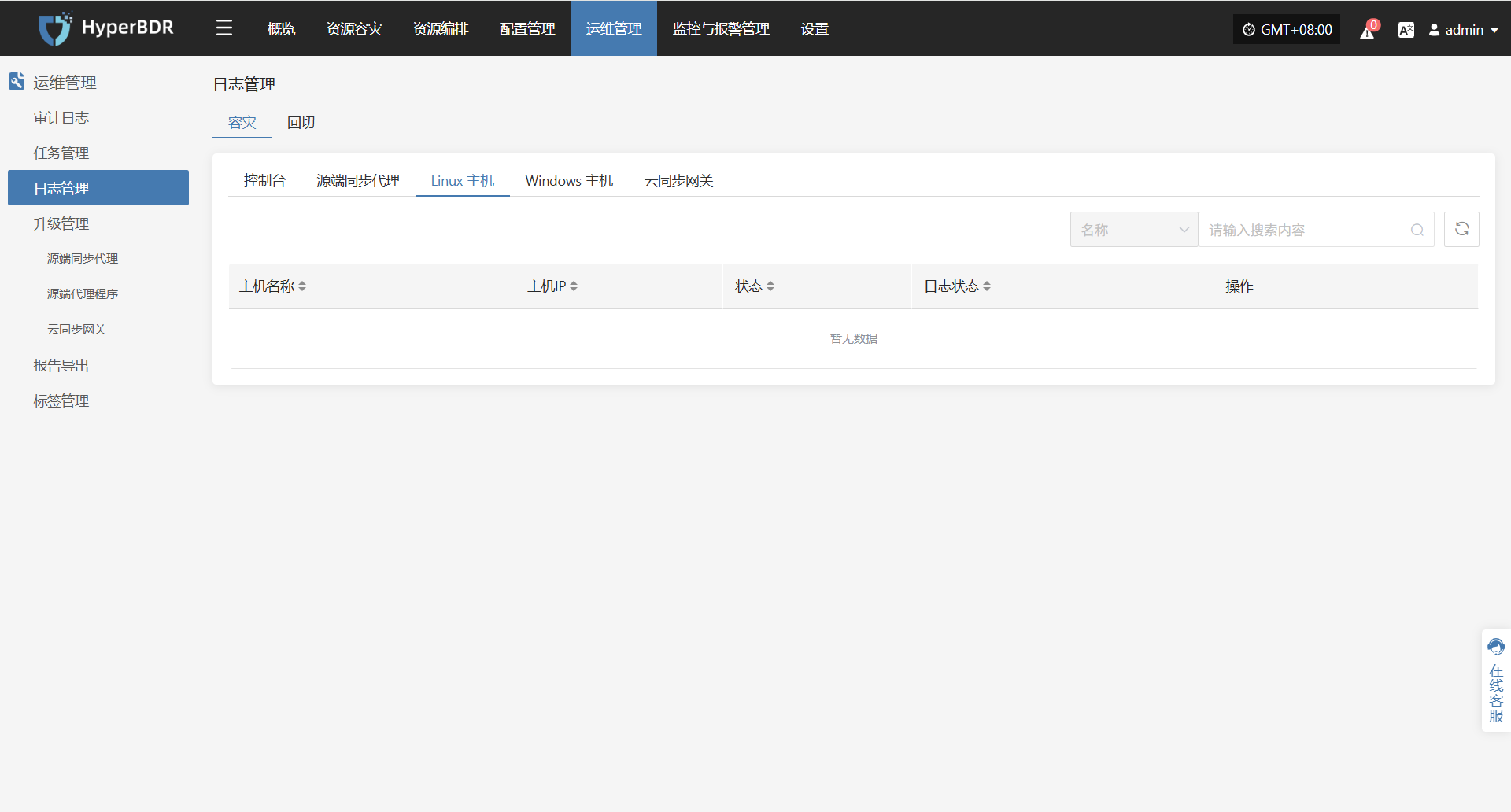
选择时间段
在弹出的对话框中设定需要收集的日志时间范围,确认后系统将自动开始日志收集
开始采集
选择时间段确认后,系统将自动开始日志收集,日志状态转换为采集中
日志下载
日志采集完成后,状态更新为“可下载”,用户可点击“点击查看列表”查看日志文件,并选择下载
配置文件管理
Linux Agent 的主要配置文件位于 /var/lib/egisplus-agent 目录下,文件名为 config.ini。该文件包含了 Linux Agent 的各项配置信息,包括服务连接、数据库、同步任务、日志、S3 配置等。
以下是该配置文件的各个部分及其作用说明:
[INFO]
Version = 6.1.0
### 应用版本号
[DEFAULT]
ServerAddress = 127.0.0.1:19982 # 服务监听地址与端口
ServerCertFile = # 服务端SSL证书文件路径(可选)
ServerKeyFile = # 服务端SSL密钥文件路径(可选)
ReadTimeout = 20 # 请求读取超时时间(秒)
WriteTimeout = 20 # 响应写入超时时间(秒)
StopTimeout = 10 # 服务停止前的等待超时(秒)
MaxHeaderBytes = 1048576 # HTTP请求头最大大小(字节)
[DATABASE]
DatabaseFile = /var/lib/egisplus-agent/agent-sync.db # SQLite 数据库文件路径
DBLogFile = /var/log/egisplus-agent/db.log # 数据库操作日志路径
[SYNC]
Deduplicate = true # 是否开启去重
Compress = "" # 数据压缩方式(空表示不开启)
Encrypt = "" # 数据加密方式(空表示不开启)
IndexPath = /var/lib/egisplus-agent/index # 索引数据存储路径
DirectIO = false # 是否启用Direct I/O
WorkersPerBlock = 2 # 每块数据的处理线程数
BuffersPerBlock = 8 # 每块数据的缓冲区数量
SaveIndexInterval = 30 # 索引保存间隔(秒)
SaveBlobInterval = 10 # Blob数据保存间隔(秒)
ConcurrentThreads = 2 # 同步任务并发线程数
SyncBufferSize = 8 # 同步缓冲区大小
EnableRetry = true # 是否启用失败重试
RetryCount = 10 # 最大重试次数
RetryInterval = 30 # 重试间隔(秒)
CheckDup = true # 是否检查重复数据
[S3]
AccessKey = ak # S3访问密钥
SecretKey = sk # S3密钥
Region = region # S3区域
BucketName = bucket # S3桶名称
StorageClass = standard # 存储类型(如 standard, infrequent-access)
URL = https:// # S3服务地址
UseTLS = true # 是否启用TLS连接
[CLIENT]
ClientCertFile = /var/lib/egisplus-agent/client_cert_file # 客户端证书文件路径
ClientKeyFile = /var/lib/egisplus-agent/client_key_file # 客户端密钥文件路径
ClientUploadURL = 120 # 客户端上传URL的超时时间(秒)
ClientTimeout = 120 # 客户端请求超时时间(秒)
SendContentMd5 = true # 是否发送Content-MD5头
DisableContentSha256 = true # 是否禁用Content-SHA256校验
[LOG]
LogPath = /var/log/egisplus-agent # 日志文件路径
LogFileName = agent-syncer.log # 日志文件名
LogLevel = info # 日志等级(如 debug, info, warn, error)
LogFileMaxSize = 64 # 单个日志文件最大大小(MB)
LogFileMaxBackups = 10 # 保留的历史日志文件数量
LogMaxAge = 28 # 日志文件最长保留天数
LogCompress = true # 是否压缩历史日志
LogStdout = false # 是否输出日志到控制台Windows Agent运维
运行环境说明
通过在源端服务器上部署 Agent 程序,实时捕获文件系统或块设备的变化,实现对数据的持续同步,适用于物理服务器、非虚拟化环境或需要更精细控制的场景。
Windows Agent 支持部署在以下版本的 Windows Server 操作系统上:2003 SP2/R2、2008、2008 R2、2012、2012 R2、2016、2019(均为 64 位)。
系统安装在 C:\Program Files (x86)\DiskSync-Agent 目录中(具体路径以实际选择安装路径为准),主要的文件及目录结构:
服务健康状态
运维人员可以通过 Windows 任务管理器检查服务的运行状态,确认服务是否正常运行。
任务管理器服务开启方式:
方法1:
同时按下键盘上 <Ctrl + Alt + Del>方法2
按下 Win + R 打开运行窗口。 输入 taskmgr,然后按 回车。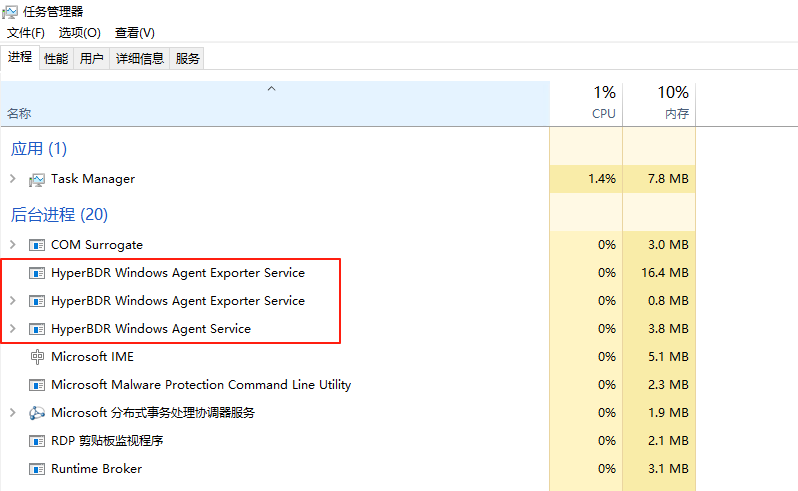
服务启动/停止/重启
启动服务:
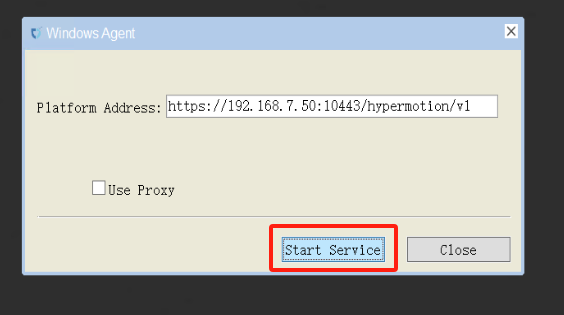
- 右键点击桌面的Windows Agent快捷程序,以管理员权限运行。
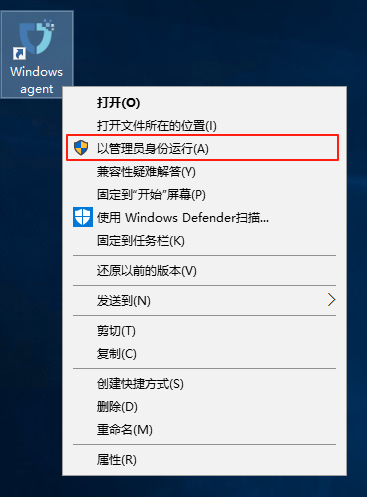
- 左键点击Start Service
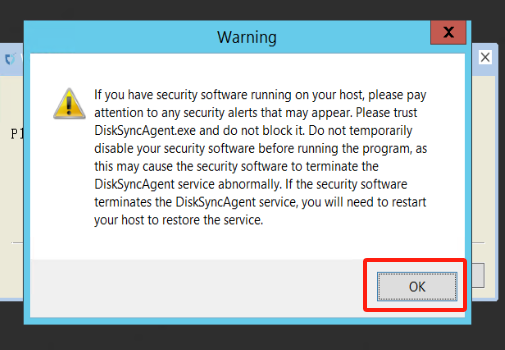
- 警告信息(忽略即可)
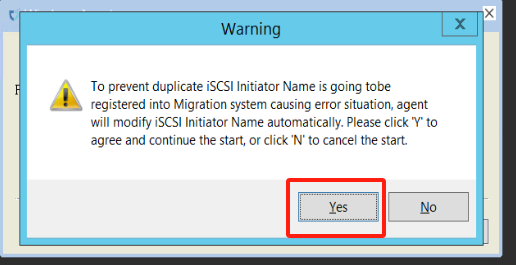
- 服务启动正常
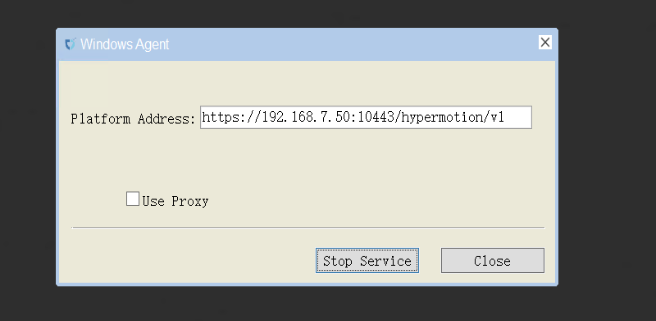
停止服务:
- 点击Stop Service即可停止服务
日志管理
所有系统日志文件存储在C:\Program Files (x86)\DiskSync-Agent\log目录中(具体路径以安装选择路径为准\log)。运维人员可以通过查看,日志文件,监控系统运行状态,排查故障,或提供相关文件给到对应项目负责人,确保系统稳定性。

日志采集
在 HyperBDR 系统中,运维人员可通过在"运维管理 > 日志管理 > 容灾|回切 > Windows主机"页面,根据实际需求,收集与下载所需日志文件,便于问题排查与系统监控。
选择需要收集的目标主机,点击对应行的“采集”操作按钮
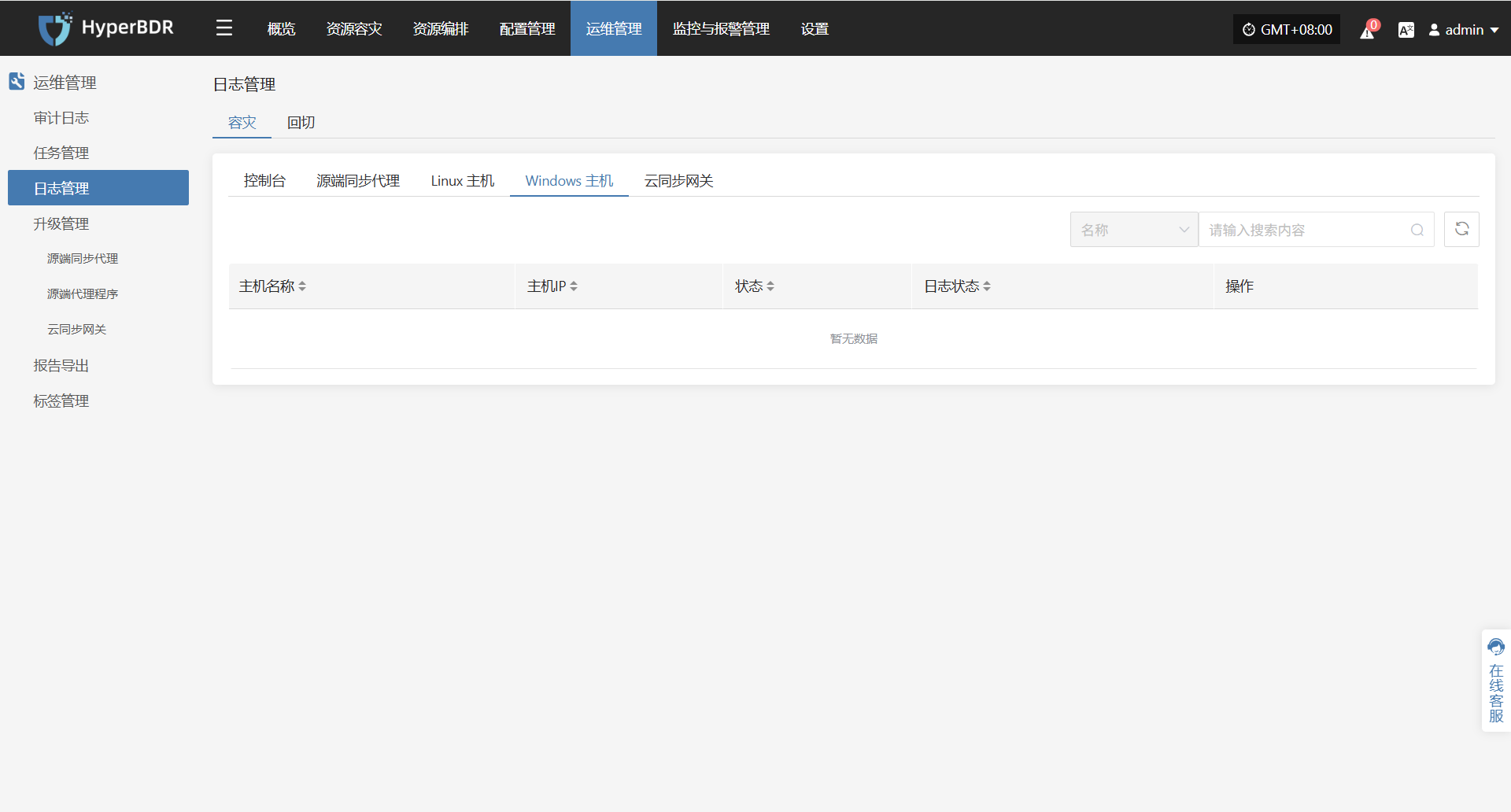
选择时间段
在弹出的对话框中设定需要收集的日志时间范围,确认后系统将自动开始日志收集
开始采集
选择时间段确认后,系统将自动开始日志收集,日志状态转换为采集中
日志下载
日志采集完成后,状态更新为“可下载”,用户可点击“点击查看列表”查看日志文件,并选择下载
配置文件管理
Windows Agent 的主要配置文件位于 C:\Program Files (x86)\DiskSync-Agent\config 目录下(具体路径以实际选择安装路径为准\config),文件名为 Sysconfig.ini。该文件包含了 Windows Agent 的各项配置信息,包括服务连接、数据库、同步任务、日志、S3 配置等。
以下是该配置文件的各个部分及其作用说明:
[SysParam]
HM_URL =https://192.168.7.141:10443/hypermotion/v1
SYNC_NODE_KEY =da8aae5b-facb-452f-8161-5c866f8fafaa
;log level
LOGFLAG=2
;Filename of successful host registration
REG_FILE=registered
;Heartbeat interval (seconds)"
HEARTBEAT_INTERVAL=50
;Whether to modify the iscsi initiator name tag, 1: modify; 0: not modify.
MODIFY_INITIATOR=1
;Used for the blobsize in iSCSI mode under non-VSS mode
COPYSIZE=3
;Proportion of cache files in partition capacity under non-VSS mode.
SWAPESPACE_PERCENT=10
;Whether to adopt the vss mode: 1. vss mode; 0. normal mode.
VSS_MODEL=1
;The proportion of volume shadow storage on the disk in VSS mode.
VSS_MAX_SIZE_PERCENT=10
;Configuration of volume shadow storage for special volumes in VSS mode, which can be configured for multiple volumes: size (G)
;VSS_SPEC_MAX_C=c:10
;The minimum proportion of free space in the volume.
FREELIMIT_PERCENT=3
apply_scene=dr
; 0: Retry after an error occurs during the synchronization process, with the retry time referring to ERRRETRY_DURATION; 1: Return an error immediately upon a synchronization error.
ERRORRETURN=0
;Maximum retry duration (in seconds) after a synchronization error.
ERRRETRY_DURATION=600
;Maximum number of blobs for hook in non-VSS mode.
HOOKBUFF_BLOCKCOUNT_MAX=256
;Minimum number of blobs for hook in non-VSS mode.
HOOKBUFF_BLOCKCOUNT_MIN=64
; 1: Write the first sector to the target disk, 0: Do not write the first sector to the target disk.
WRITE_FIRST_SECTOR=0
;Maximum number of write threads in object storage mode.
THREAD_COUNT=4
;thread interval(millisecond)
THREAD_INTERVAL=25
;Whether to send the metafile (including the local metafile) to the object storage.
WRITE_OSS_META=0
;The maximum CPU usage allowed for the process. The actual CPU usage of the process may fluctuate up and down, and online update is supported.
CPU_USEAGE_SETTING=30
;Specify the disks that do not require synchronization. When there are multiple disks, separate the disk numbers with commas. For example: EXCLUDE_DISKS=1,2. The default is EXCLUDE_DISKS=NULL, which synchronizes all disks.
EXCLUDE_DISKS=NULL
;iscsi service parameters
MaxRequestHoldTime=120
SrbTimeoutDelta=120
LinkDownTime=15
InitialR2T=1
ImmediateData=0
FirstBurstLength=16384
MaxBurstLength=16384
MaxRecvDataSegmentLength=8192
ISCSI_SYNC_STATUS=0
ISCSI_PROTECT_STATUS=0
hyper_exporter_id=c85eb10e1a8f4dd58080d9cbe0d71bf4
LOCAL_LAN=1
use_proxy=0
VSS_CHECK_RESULT=1云同步网关运维
运行环境说明
云同步网关是连接源端与目标云平台的关键组件,负责接收并处理源端的全量和增量数据,将其同步至云平台的存储中,实现高效、低成本的数据备份与灾难恢复。
平台会自动创建默认云同步网关环境,通常为 2 核 CPU、4GB 内存、50GB 硬盘的 Ubuntu 24.04 系统。
系统安装在 /var/lib/sgateway 目录中(位置可选),主要的文件及目录结构:
/var/lib/sgateway/
├── certs # 存放 TLS/SSL 证书的目录(含私钥、公钥等)
├── config # 存放配置文件的目录(如 s3block_config.ini)
├── confmgmt # 配置管理目录,可能用于集中配置同步或版本控制
├── diskdir # 本地数据目录,用于对象存储数据或缓存
├── dr # 灾难恢复(Disaster Recovery)相关目录(当前可能为空或预留)
├── logs # 日志目录,记录 s3block 和 watchman 的运行日志
├── s3block # s3block 主程序,可执行文件,提供核心数据服务
├── s3block.db # s3block 的本地数据库文件,存储任务状态、元信息等
├── s3block.service # systemd 服务定义文件,用于管理 s3block 的启动和运行
├── s3block_version # s3block 的版本信息文件
├── version # 系统或模块的版本号标识文件
├── watchman # watchman 主程序,可执行文件,负责监控、同步触发等功能
└── watchman.service # systemd 服务定义文件,用于管理 watchman 的启动和运行服务健康状态
云同步网关创建安装完成后,通过 systemd工具进行运行和管理。运维人员可使用systemctl相关命令检查服务状态与执行控制操作。云同步网关需要关注两个服务分别是:s3block.service、watchman.service和hyper_exporter.service
| 服务项 | 关注字段 | 服务状态 |
|---|---|---|
| s3block.service | Active | active (running) |
| watchman.service | Active | active (running) |
| hyper_exporter.service | Active | active (running) |
可以通过systemctl status <服务名称>进行检查服务状态,非active状态以外都为异常,需要进行一步排查问题并解决。下列为查询示例:
systemctl status s3block.service服务启动/停止/重启
运维人员可通过systemd用以下命令对 s3block.service和watchman.service进行管理:
启动服务
s3block.service
systemctl start s3block.servicewatchman.service
systemctl start watchman.service停止服务
s3block.service
systemctl stop s3block.servicewatchman.service
systemctl stop watchman.service重启服务
s3block.service
systemctl restart s3block.servicewatchman.service
systemctl restart watchman.service
日志管理
所有系统日志文件存储在/var/log/sgateway 目录中。运维人员可以通过查看,日志文件,监控系统运行状态,排查故障,或提供相关文件给到对应项目负责人,确保系统稳定性。
/var/log/sgateway/
├── s3block_20250514.log # s3block 模块在 2025-05-14 的运行日志
├── s3block_20250515.log # s3block 模块在 2025-05-15 的运行日志
├── watchman_20250514.log # watchman 模块在 2025-05-14 的运行日志
└── watchman_20250515.log # watchman 模块在 2025-05-15 的运行日志日志采集
在 HyperBDR 系统中,运维人员可通过在"运维管理 > 日志管理 > 容灾|回切 > 云同步网关"页面,根据实际需求,收集与下载所需日志文件,便于问题排查与系统监控。
选择需要收集的目标主机,点击对应行的“采集”操作按钮
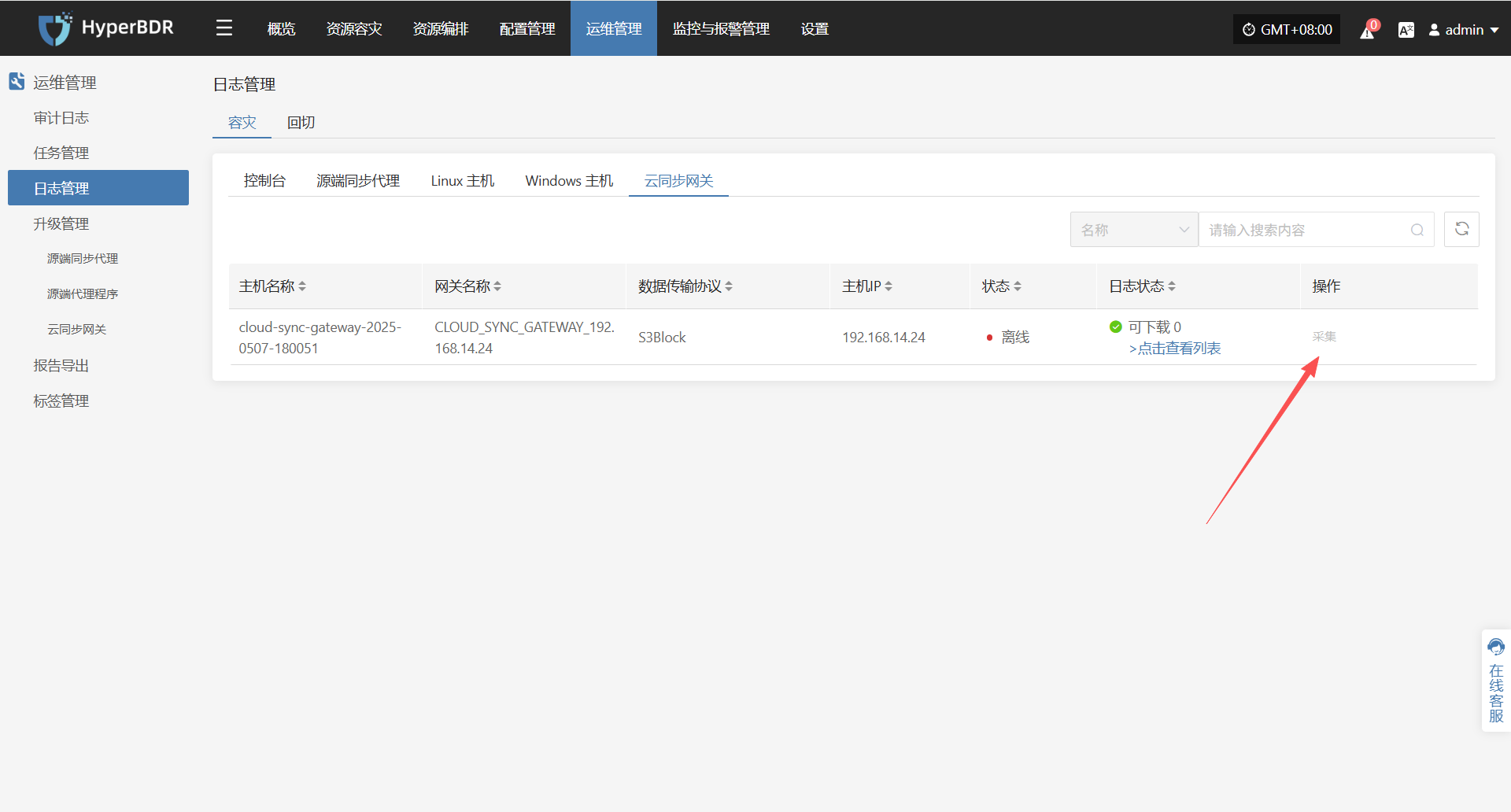
选择时间段
在弹出的对话框中设定需要收集的日志时间范围,确认后系统将自动开始日志收集
开始采集
选择时间段确认后,系统将自动开始日志收集,日志状态转换为采集中
日志下载
日志采集完成后,状态更新为“可下载”,用户可点击“点击查看列表”查看日志文件,并选择下载
配置文件管理
云同步网关的主要配置文件为 s3block_config.ini,位于 /var/lib/sgateway/config 目录下。该文件包含网关标识、公网 IP、WebSocket 服务地址、本地数据目录、日志等级、S3 存储访问凭证、端点地址等关键信息,用于支撑网关与中心服务之间的数据同步与通信。
以下是该配置文件的各个部分及其作用说明: 以下是该配置文件的各个部分及其作用说明:
[system]
gateway_uuid = 41f2ef9e-50c7-430f-b316-e9e4ec5516d4 # 网关唯一标识符(UUID)
websocket_server = wss://192.168.7.141:10443/duplex/gateway/v1 # 与服务端建立 WebSocket 双向通信的地址
filedir = diskdir # 本地数据存储目录路径(相对路径)
log_level = 1 # 日志等级(1 表示 INFO 级别)
multi_srv = true # 是否启用多服务模式(true 表示启用)
public_ip = 192.168.14.65 # 网关对外通信的公网 IP 地址
accessKey = wCi7qC8RlFydraCugWWa # 对象存储服务的访问密钥(Access Key)
secretAccessKey = TH5g4gbJKsK2YEsBLj7GaFpbWTiGYarRQSu1B59t # 对象存储服务的密钥(Secret Access Key)
localdisksaved = # 本地磁盘持久化目录(当前为空,可能为默认路径)
endpoint = https://192.168.14.65:13260 # 对象存储服务的 endpoint(API 请求地址)
bucketcreated = true # Bucket 是否已创建(true 表示已创建)临时过渡主机镜像运维
运行环境说明
“临时过渡主机镜像”是用于在系统迁移、故障恢复或测试验证等场景下,快速创建云主机的临时镜像,确保业务平稳过渡。创建时需要保持与回切主机配置一致
升级管理
控制台
控制台支持在线升级,过程平滑,配置文件和数据保留,适用于日常版本维护、功能增强及问题修复,确保系统持续稳定运行。
升级准备
整体升级
在开始操作前,请务必联系项目负责人或直接访问 OnePro 线上docs官网获取最新安装包,以完成后续升级。 点击获取安装包
将安装包上传至服务器
解压至指定目录,例如:
tar zxvf <更新包>.tar.gz -C /更新包解压路径单个模块升级
开始之前请联系项目负责人获取最新模块包以完成后续升级操作。
将安装包上传至服务器
创建更新包目录
mkdir -p /root/upgrade_$(date +%Y%m%d)- 上传更新包到新创建目录下
执行升级
整体升级
- 执行升级命令,系统将自动加载更新内容至运行目录
/opt/installer/production/venvs:
cd /opt/installer/production/scripts
./hmctl upgrade /更新包解压路径/installer/venvs单个模块升级
- 执行升级命令,系统将自动加载更新内容至运行目录
/opt/installer/production/venvs:
cd /opt/installer/production/scripts
./hmctl upgrade /root/upgrade_$(date +%Y%m%d)/源端同步代理(Sync Proxy)
升级准备
系统支持通过平台前端页面执行组件升级,过程平滑,配置无损,适用于日常版本维护与功能更新。
在组件升级过程中,同样需要完成上述升级包准备与部署步骤。
执行升级
用户可以通过浏览器访问平台登录页面,输入有效的用户名和密码进行身份验证,成功登录后即可在线升级。
运维管理--升级管理--源端同步代理
当1.2步骤操作完成后,对应位置会有相应升级提示
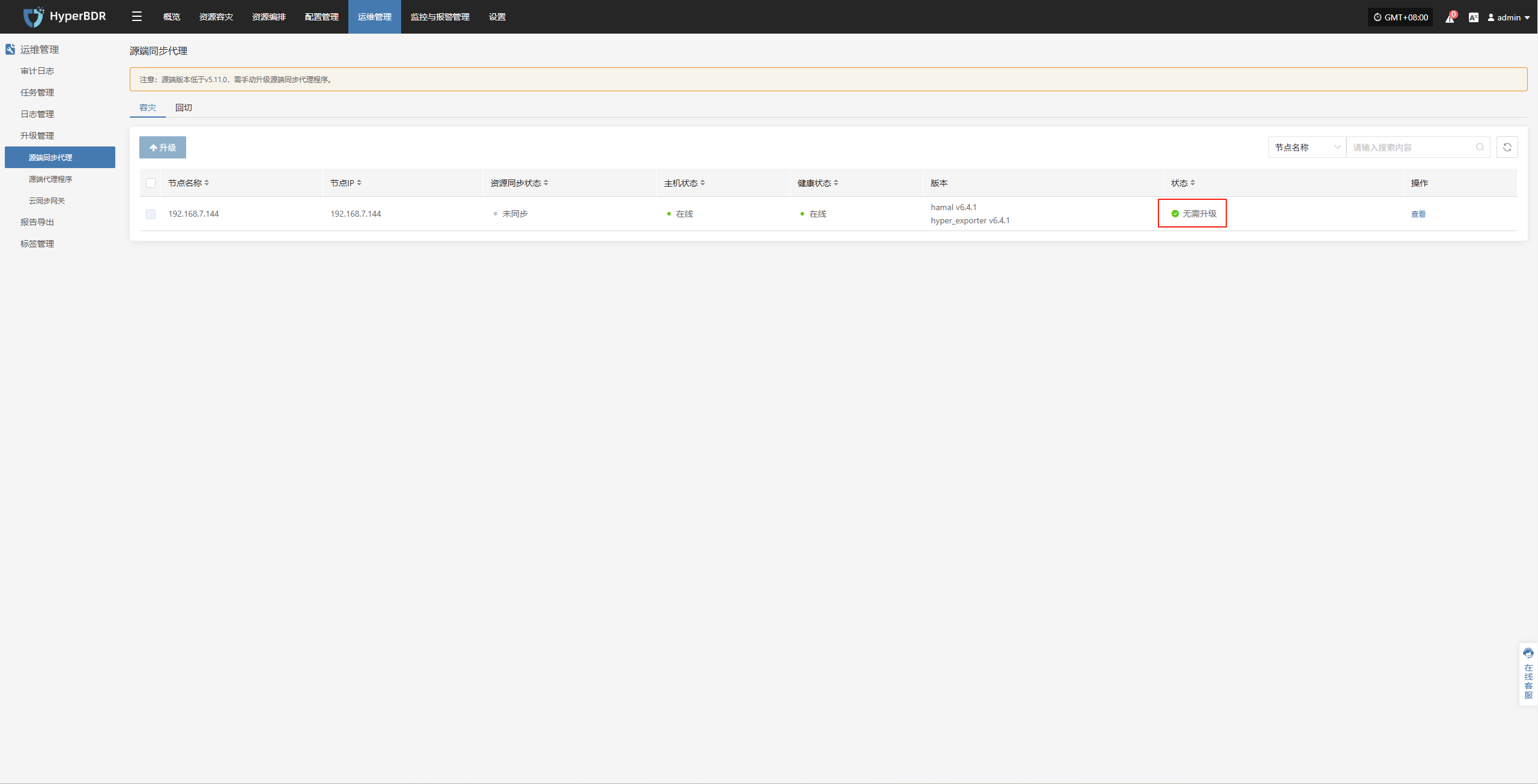
Linux Agent
升级准备
系统支持通过平台前端页面执行组件升级,过程平滑,配置无损,适用于日常版本维护与功能更新。
在组件升级过程中,同样需要完成上述升级包准备与部署步骤。
执行升级
用户可以通过浏览器访问平台登录页面,输入有效的用户名和密码进行身份验证,成功登录后即可在线升级。
运维管理--升级管理--源端代理程序
当1.2步骤操作完成后,对应位置会有相应升级提示
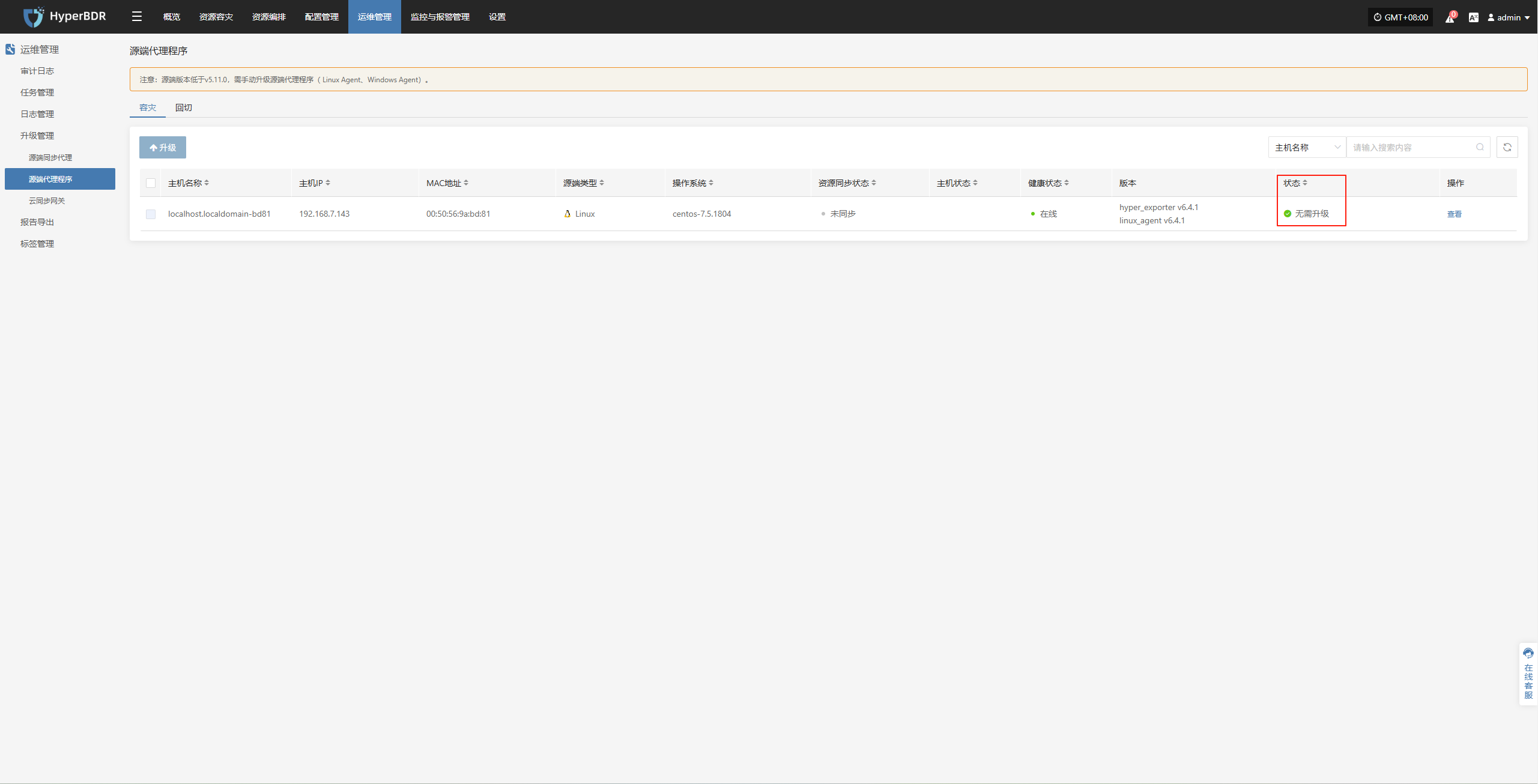
Windows Agent
升级准备
系统支持通过平台前端页面执行组件升级,过程平滑,配置无损,适用于日常版本维护与功能更新。
在组件升级过程中,同样需要完成上述升级包准备与部署步骤。
执行升级
用户可以通过浏览器访问平台登录页面,输入有效的用户名和密码进行身份验证,成功登录后即可在线升级。
运维管理--升级管理--源端代理程序
当1.2步骤操作完成后,对应位置会有相应升级提示
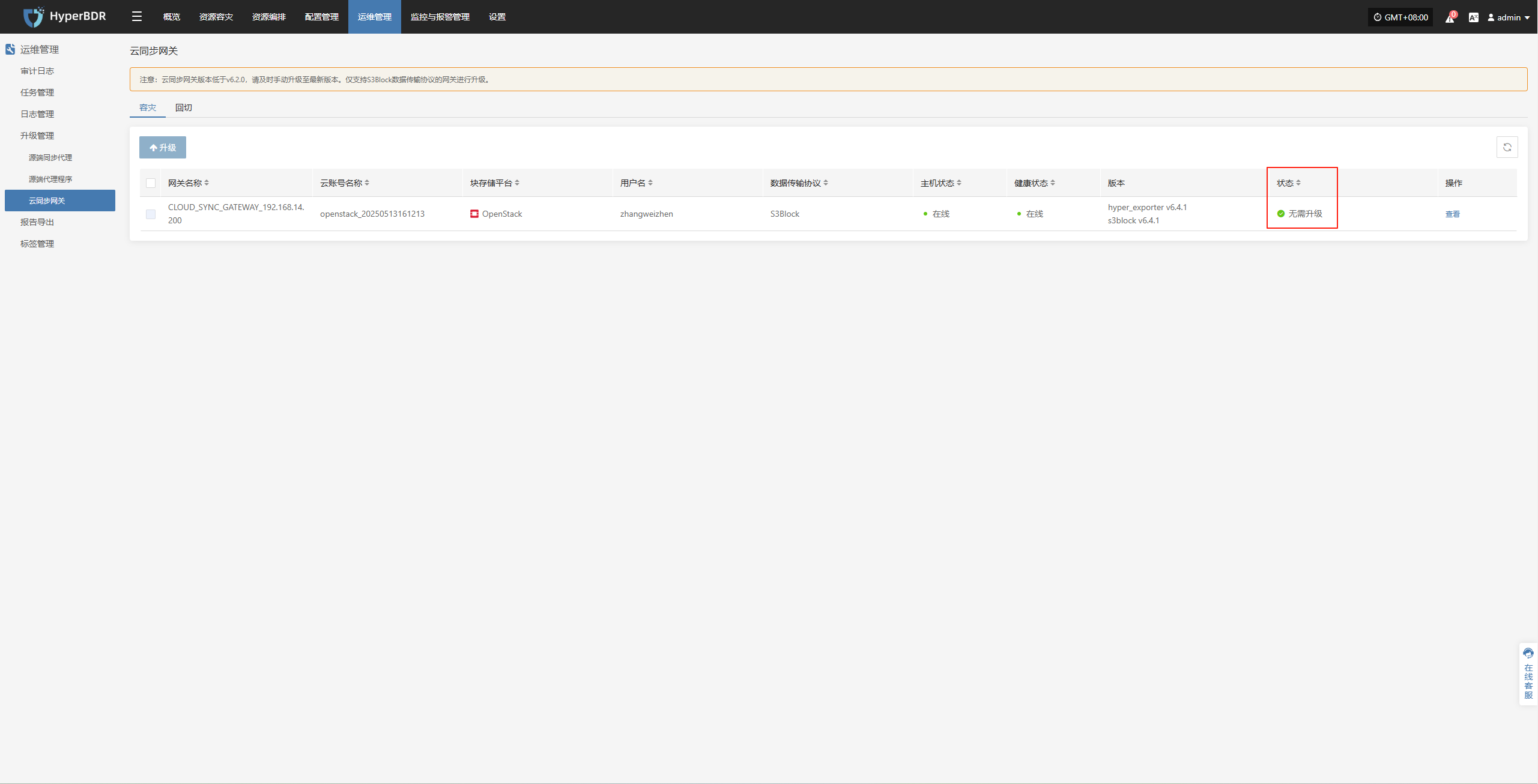
云同步网关
升级准备
系统支持通过平台前端页面执行组件升级,过程平滑,配置无损,适用于日常版本维护与功能更新。
在组件升级过程中,同样需要完成上述升级包准备与部署步骤。
执行升级
用户可以通过浏览器访问平台登录页面,输入有效的用户名和密码进行身份验证,成功登录后即可在线升级。
运维管理--升级管理--云同步网关
当1.2步骤操作完成后,对应位置会有相应升级提示
临时过渡主机镜像
升级准备
系统支持通过平台前端页面执行组件升级,过程平滑,配置无损,适用于日常版本维护与功能更新。
在组件升级过程中,同样需要完成上述升级包准备与部署步骤。
执行升级
用户可以通过浏览器访问平台登录页面,输入有效的用户名和密码进行身份验证,成功登录后即可在线升级。
因该过度主机特殊性,升级时需要重新配置
配置管理--容灾恢复平台配置--通用模式--回切--添加
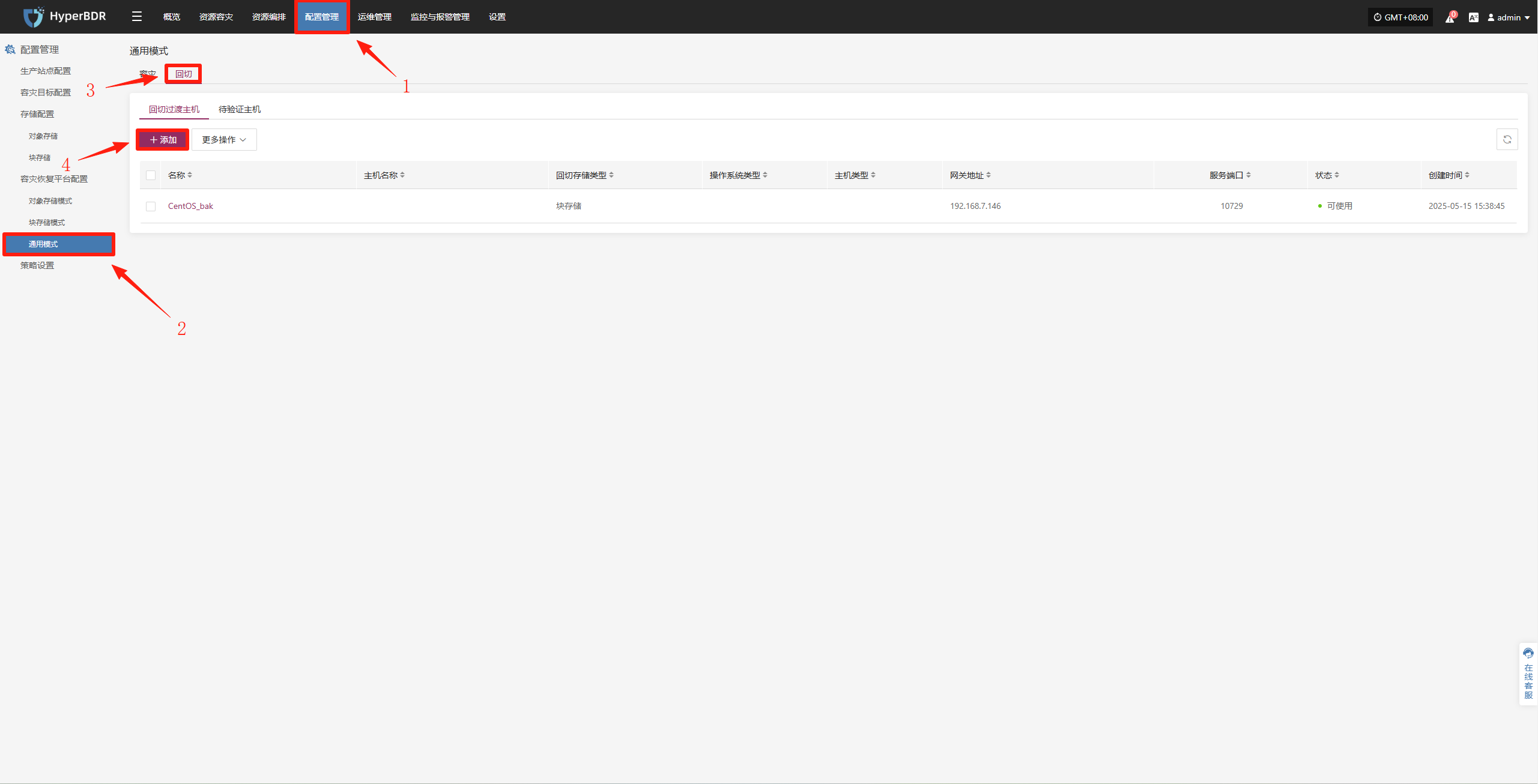
根据实际情况下载最新临时过渡主机镜像,重新创建临时过渡主机
报告管理
报告类型
支持的报告类型与说明
目前可通过 HyperBDR 控制台导出各类系统运行与管理报告,便于用户对系统状态进行定期分析与归档。
| 报告类型 | 报告说明 |
|---|---|
| 主机容灾汇总报告 | 统计当前租户下已注册和已解除注册的所有主机的基本信息,包括同步次数、演练次数、接管次数、系统类型等 |
| 主机同步数据详细报告 | 统计当前租户下已注册和已解除注册的所有主机的同步任务详情 |
| 主机容灾演练详细报告 | 统计当前租户下已注册和已解除注册的所有主机的演练任务详情 |
| 主机容灾接管详细报告 | 统计当前租户下已注册和已解除注册的所有主机的接管任务详情 |
| 主机容灾周期汇总报告(天) | 统计当前租户下已注册和已解除注册的 |
| 容灾云同步网关汇总报告 | 统计当前租户下所有云同步网关的基本信息 |
| 容灾云同步网关详细报告 | 统计当前租户下所有云同步网关的详细信息,精确到每块磁盘 |
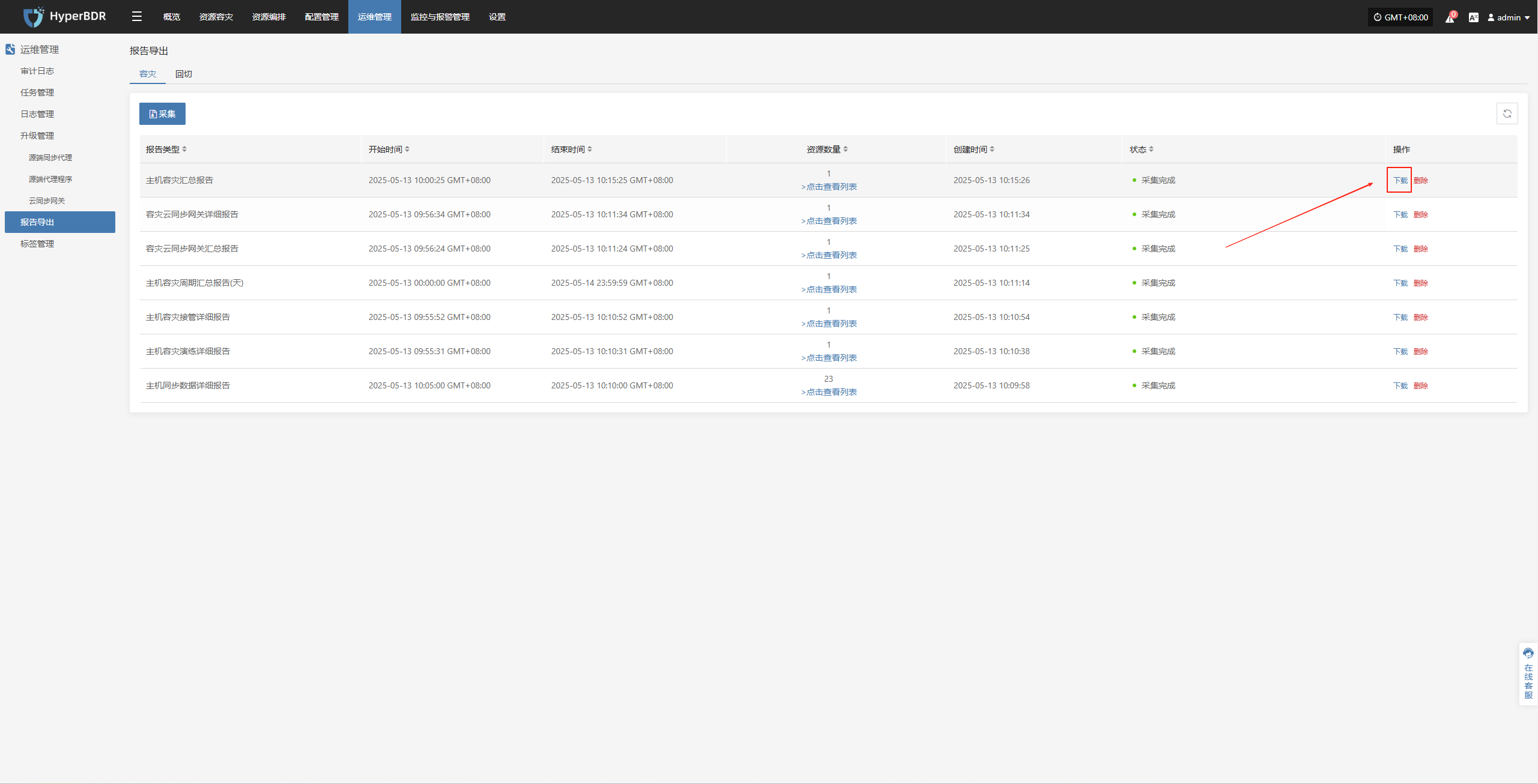
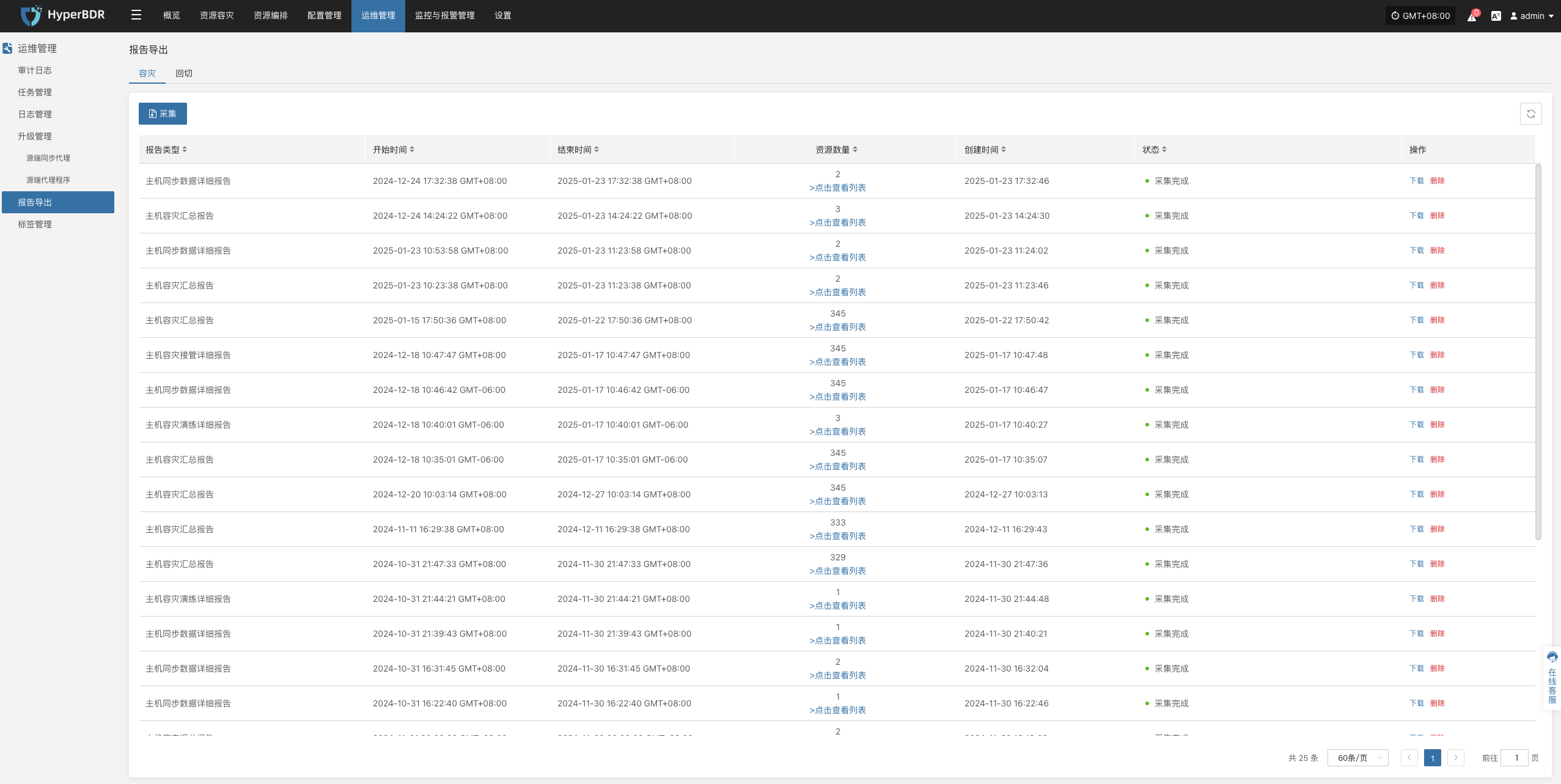
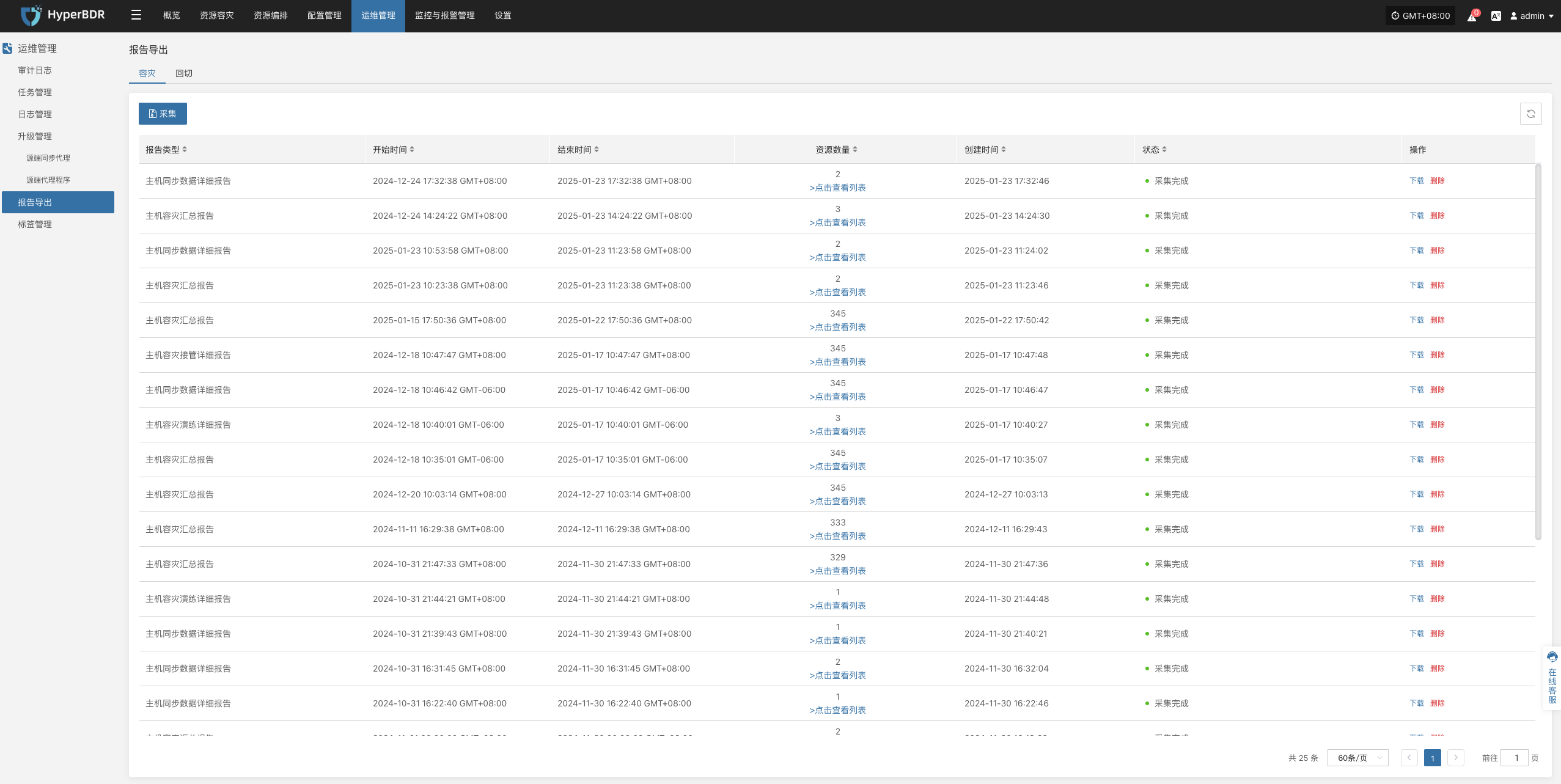
报告导出
报告导出操作示例
登录到 HyperBDR-HyperMotion 控制台
- 注意:如果需要下载不同租户的主机信息报表,需要不同租户所属的用户登录控制台进行操作。
点击【操作】>【报表】,进入报表页面。
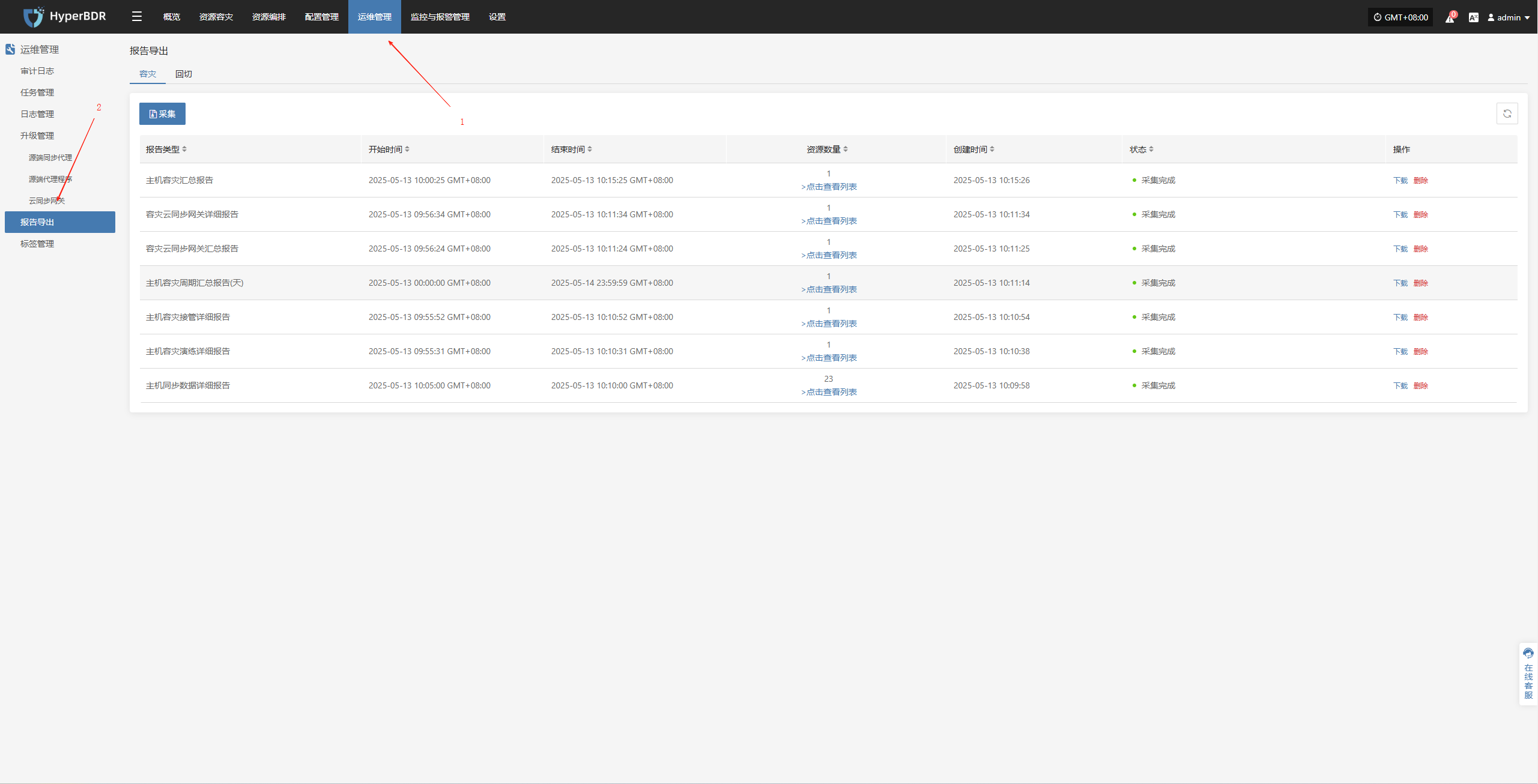
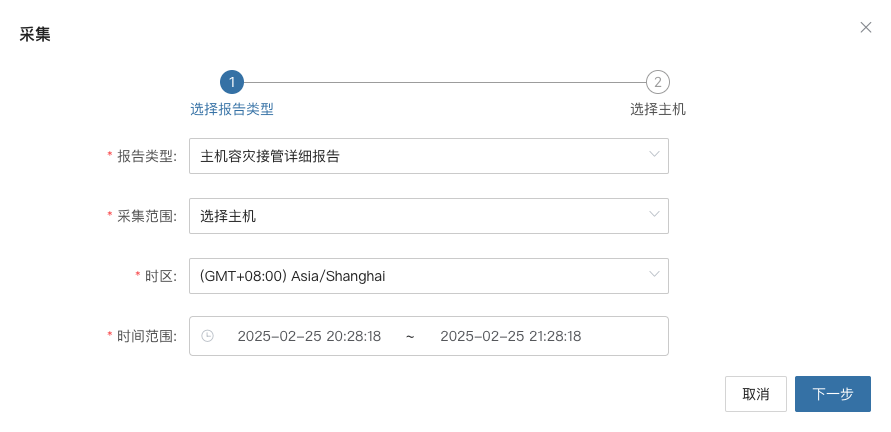
收集报表
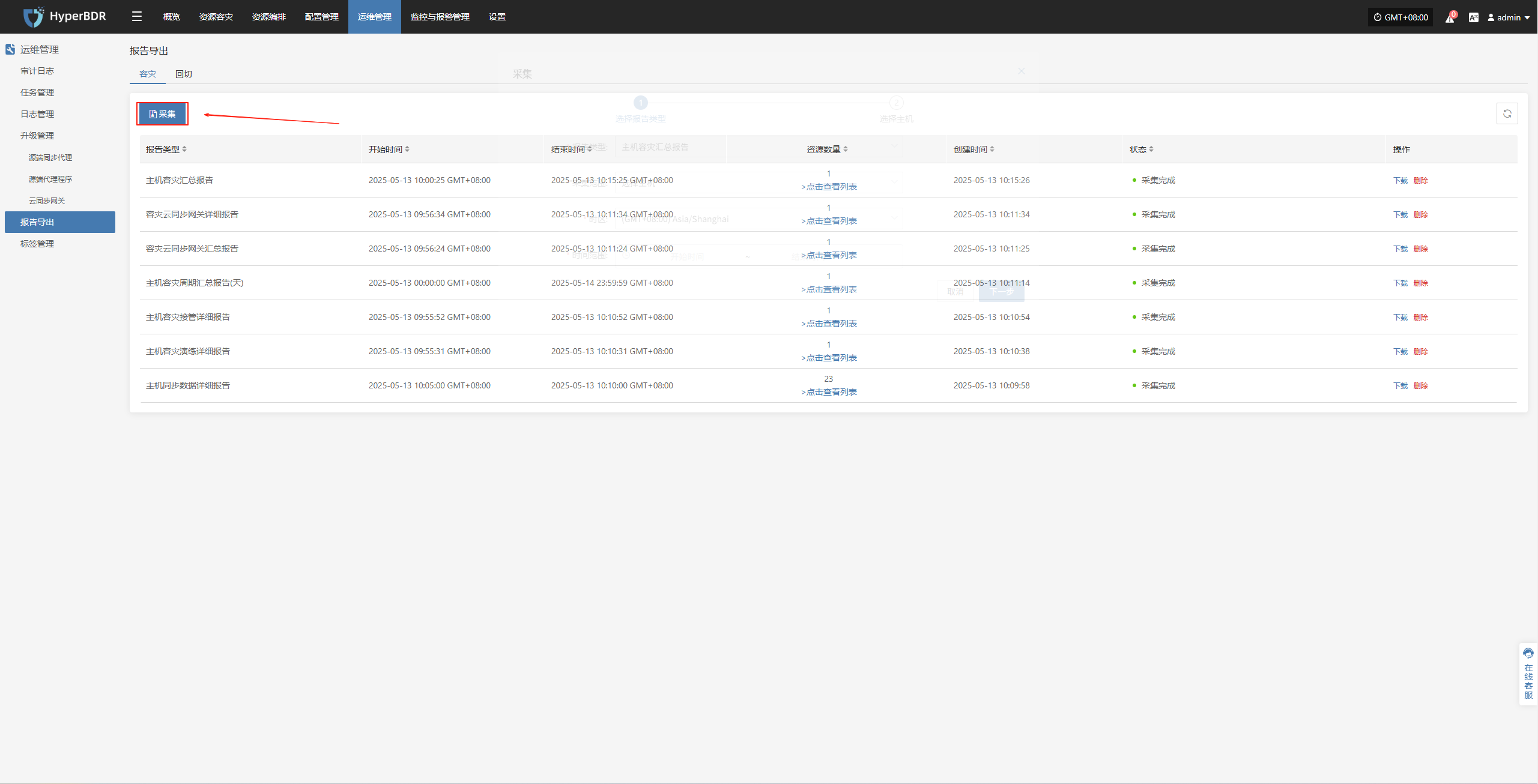
根据需要选择报表类型、范围、时区、时间范围,确认信息后点击【提交】
下载报告
- 点击[下载]报告
监控告警管理
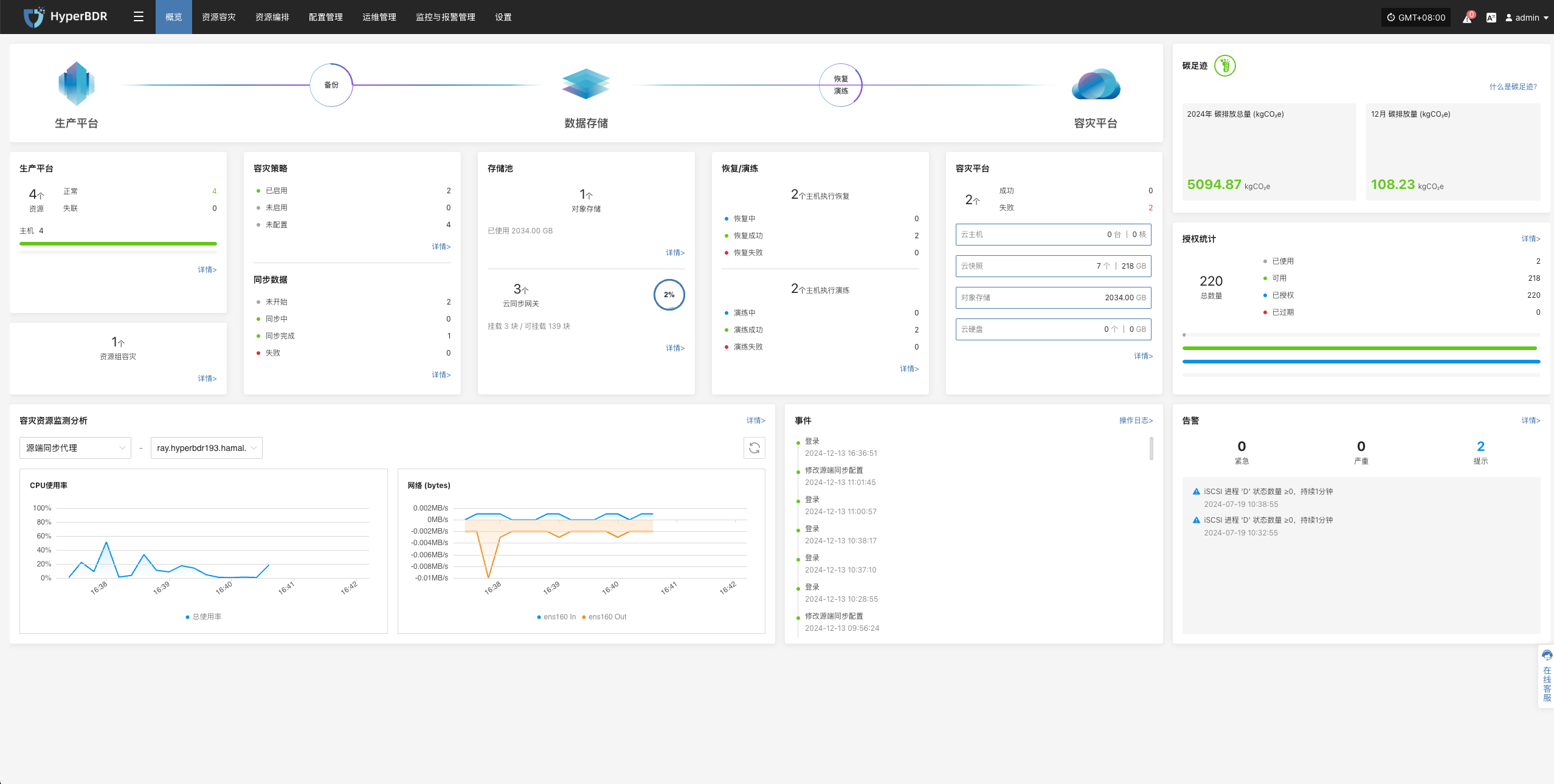
概览展示
HyperBDR 会提供的容灾概览监控界面,概览界面展示整个容灾平台所涉及到的资源及相关数据汇总信息,可以更加直观看到整个容灾平台的运行状态。
关键指标
系统层面
CPU / 内存使用率:识别是否存在资源瓶颈。
并发任务数:监控当前正在执行的备份/恢复/同步任务数量。
网络吞吐量:关注数据传输速度,评估是否存在网络拥塞。
恢复/演练层面
任务成功率:备份或恢复任务失败率超过阈值时需及时告警。
快照数量与大小:监控快照占用的存储空间,避免存储耗尽。
资源占用:包含云主机、云存储等资源占用情况。
告警与事件
告警等级分布:统计当前告警的等级(信息、警告、严重),优先处理高等级告警。
事件趋势:观察一定周期内(如 7 天、30 天)告警数量变化,及时发现潜在问题。
告警配置与响应
告警阈值设定
针对 CPU、内存、网络、任务失败率等核心指标,设置合理的阈值并分级(警告、严重、紧急)。
对关键任务事件(如备份任务)可设置更严格的告警条件。
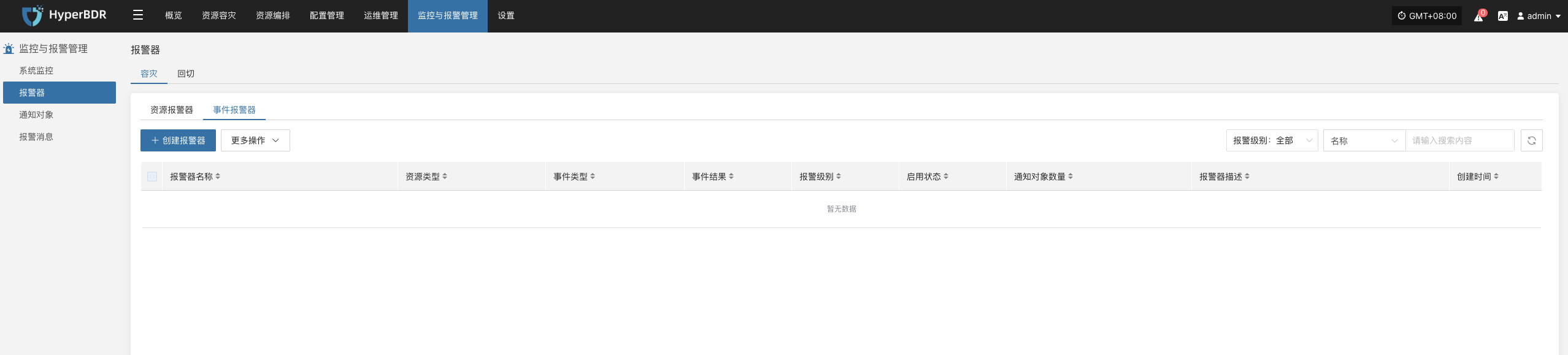
目前支持对资源和事件创建告警,
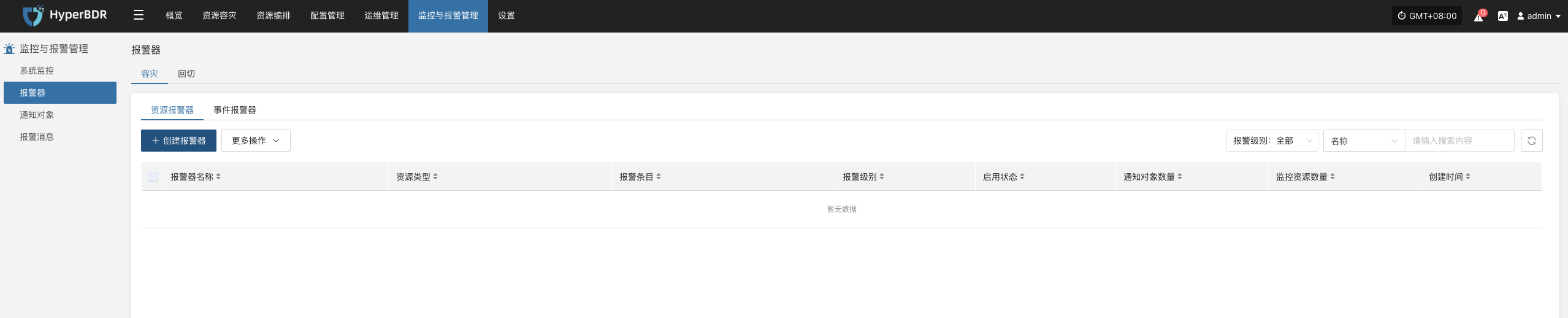
- 创建资源报警器
定义报警器名称、报警器级别、资源类型,包含CPU、内存、磁盘、进程进行资源告警配置,达到一定的阀值进行告警事件的发送。
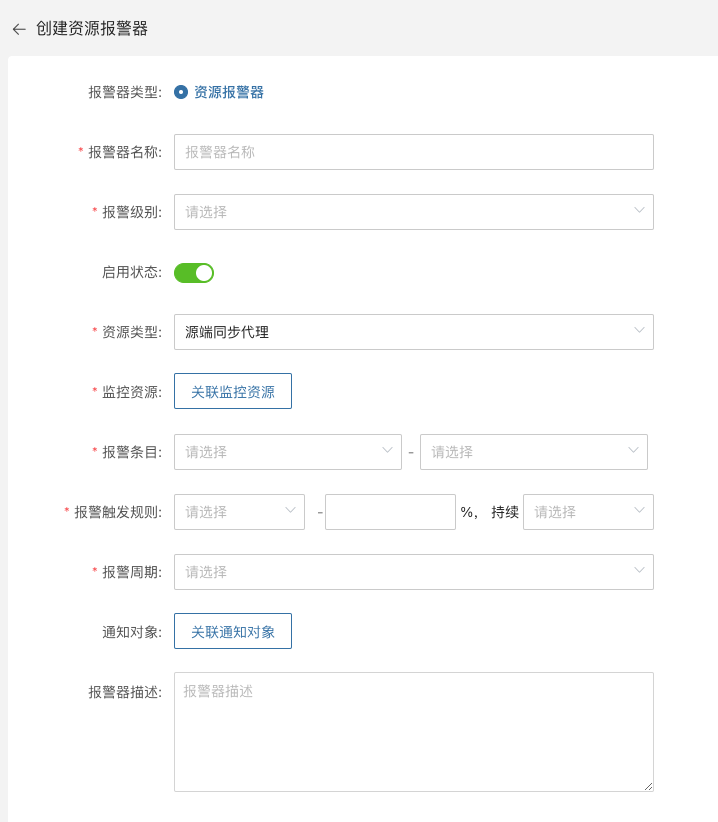
- 创建事件告警
定义事件报警器名称、报警器级别、事件类型,包含容灾主机资源、生产平台资源、容灾平台资源等进行事件告警配置,触发事件之后进行告警事件的发送。
重要的告警指标
事件类型:容灾主机资源 “主机失联”,事件结果为“成功”。
事件类型:容灾主机资源 “同步主机”,事件结果为“失败”。
事件类型:容灾主机资源 “启动主机”,事件结果为“失败”。
其他监控指标,可以按照需求进行配置。
多渠道通知
配置邮件、短信、IM(如钉钉、微信企业号)等多种告警渠道,确保第一时间获知问题。
邮件告警通道
- 短信告警通道
- WebHook告警通道
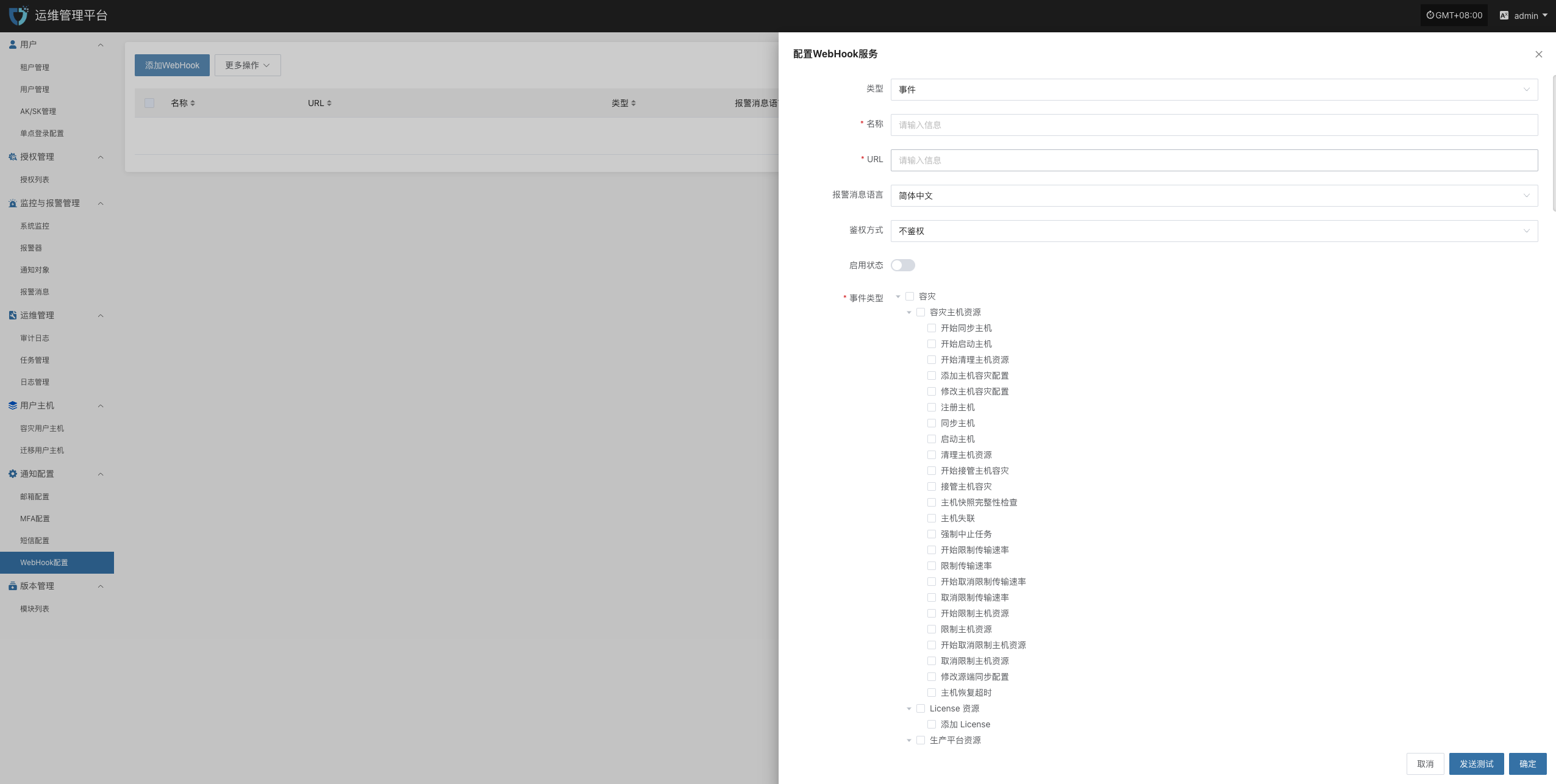
告警响应流程
运维人员收到告警后,应在规定 SLA 时间内进行排查和处理。
处理完毕后,更新工单系统或日志,记录故障原因、处理步骤与结果。
告警配置最佳实践
资源告警
为保障系统运行的稳定性与资源使用的可控性,已对 CPU、内存及磁盘等关键资源项设置了基础告警阈值。当资源使用率超过设定的预警值时,系统将自动触发告警通知,以便运维人员及时响应与处理,避免资源瓶颈对业务造成影响。
| 资源类型 | 告警指标 | 告警规则 | 告警级别 | 备注 |
|---|---|---|---|---|
| 主机 | CPU 使用率 | ≥ 80%,持续 5 分钟 | 严重 | |
| 主机 | 内存使用百分比 | ≥ 80%,持续 5 分钟 | 严重 | |
| 主机 | 根磁盘已使用容量百分比 | ≥ 80%,持续 5 分钟 | 严重 | |
| 主机 | 不健康容器数量统计 | ≥ 1 个,持续 5 分钟 | 严重 | |
| RabbitMQ | 队列消息数量 | ≥ 10 个,持续 5 分钟 | 严重 |
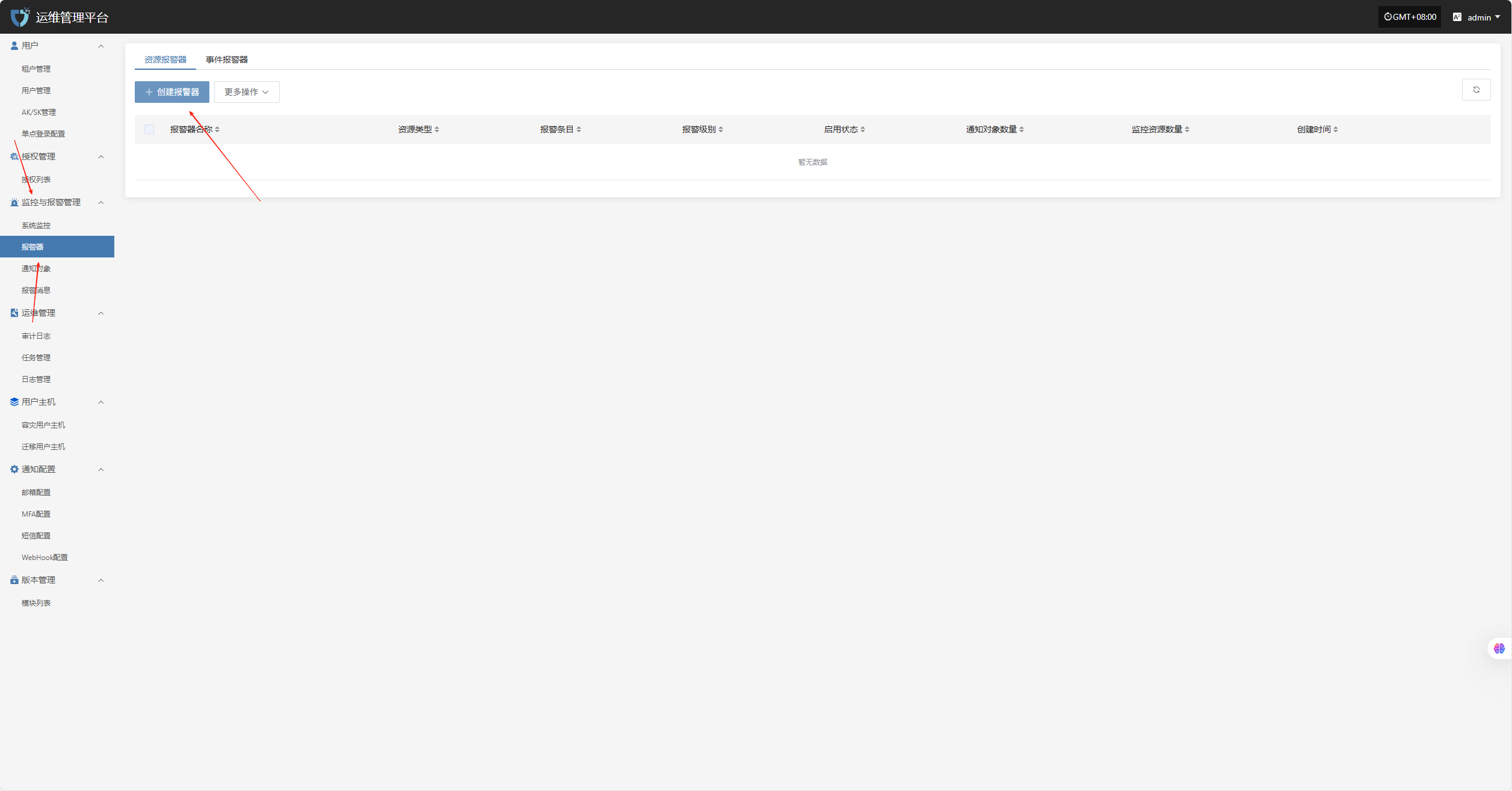
配置示例:CPU 资源-告警配置
登录至运维管理平台:IP:30443
监控与报警管理--报警器--创建报警器
根据实际情况填写对应级别名称,并根据上述表格明确监控范围
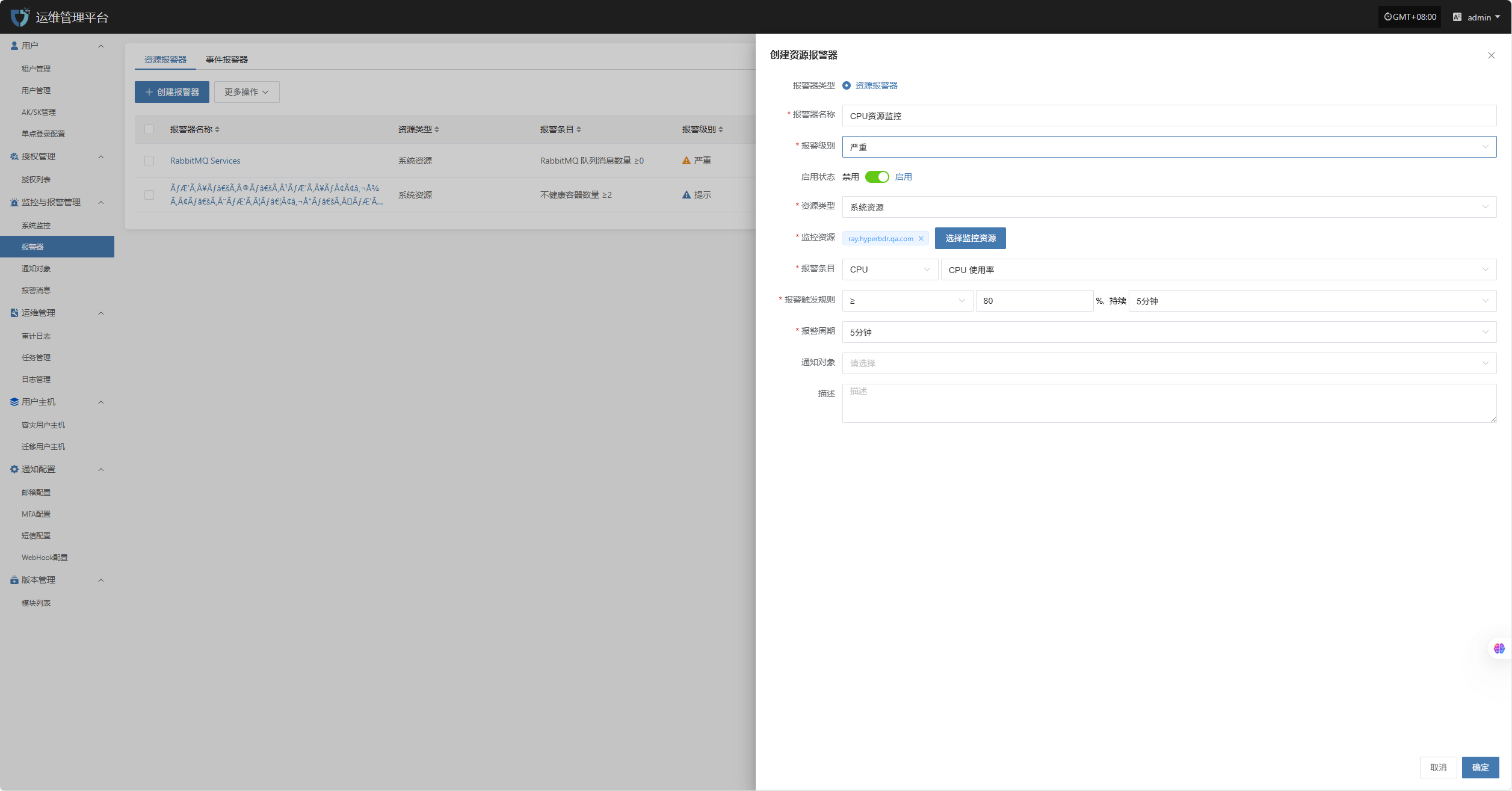
完成创建
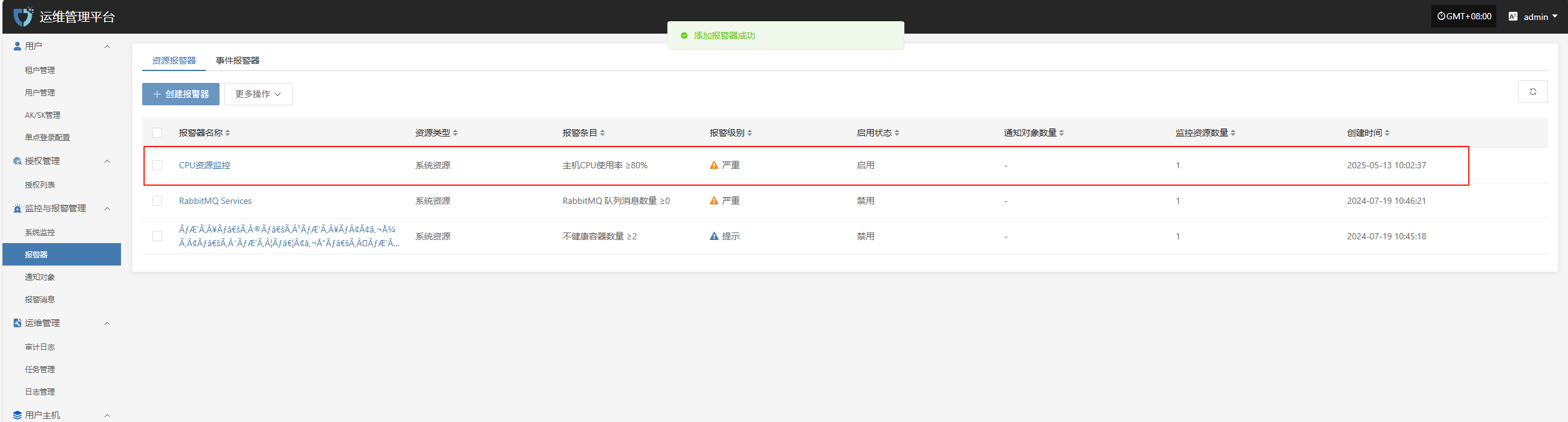
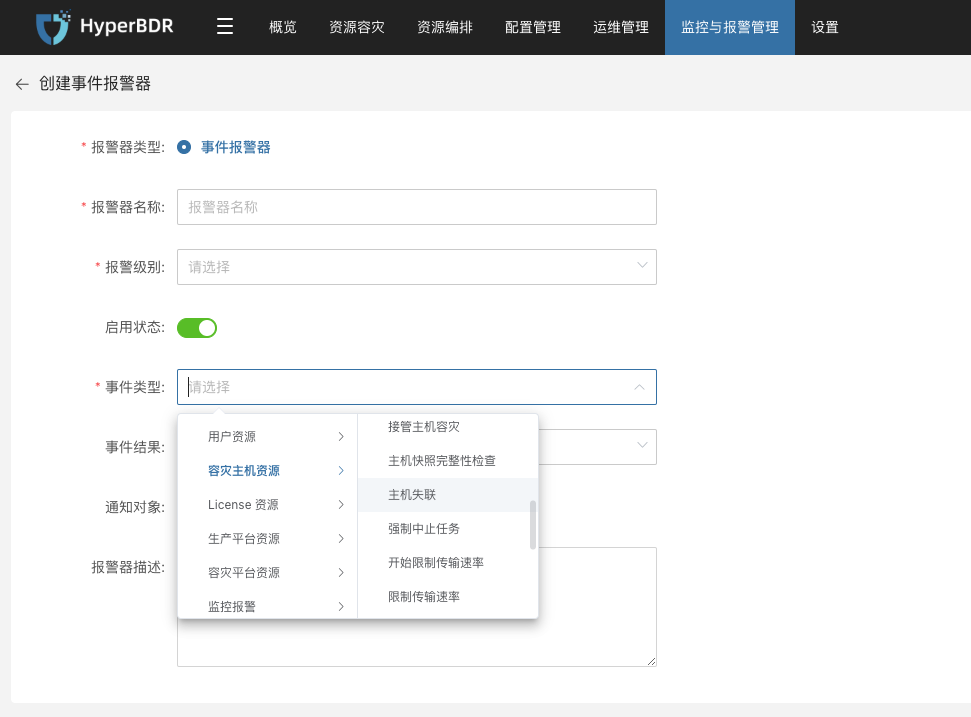
事件告警
为保障系统运行的安全性与可观测性,已对容灾主机的关键操作行为与异常状态设置了事件监控策略。系统将在检测到如主机失联、同步失败、启动异常等事件时,自动记录并触发告警通知,协助运维人员快速定位问题并及时处理,降低潜在风险对业务的影响。
| 监控资源 | 事件类型 | 事件结果 | 告警级别 | 备注 |
|---|---|---|---|---|
| 事件 | 主机失联 | 成功 | 严重 | |
| 事件 | 同步主机 | 失败 | 严重 | |
| 事件 | 启动主机 | 失败 | 严重 |
配置示例:同步数据失败-告警配置
登录至控制台:IP:30443

监控与报警管理--报警器--事件报警器--创建报警器
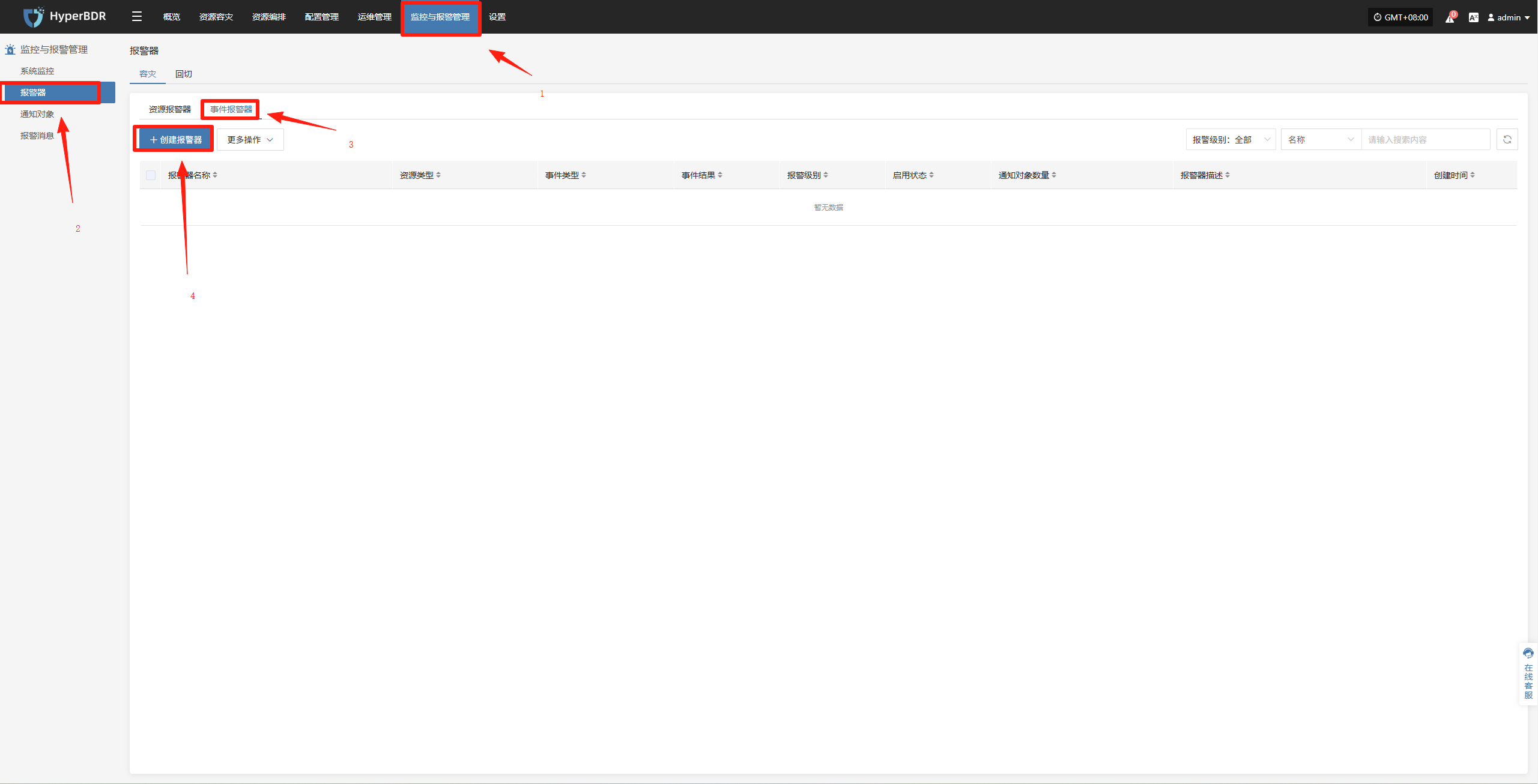
根据实际情况选择填写对应监控事件类型
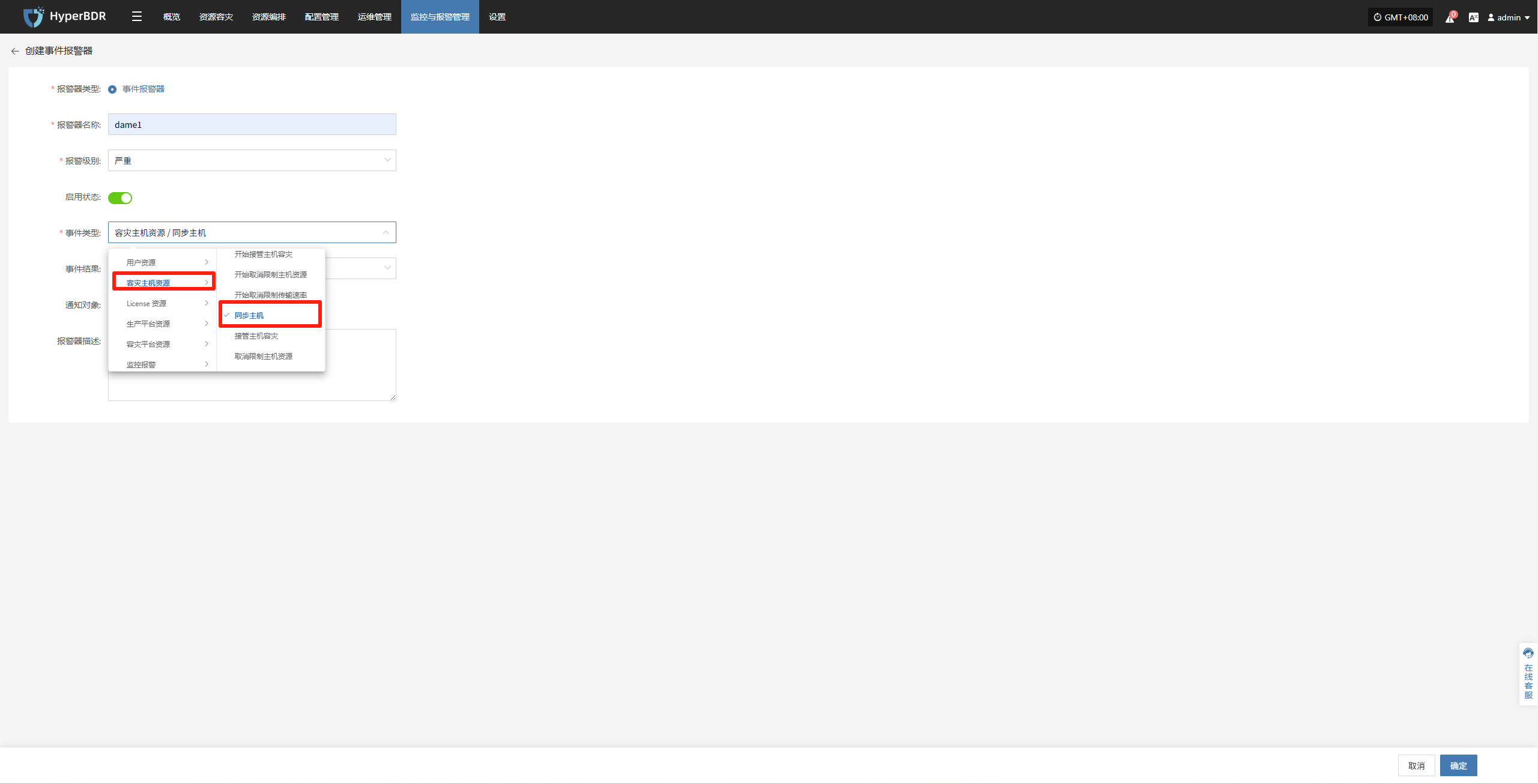
明确监控事件类型结果
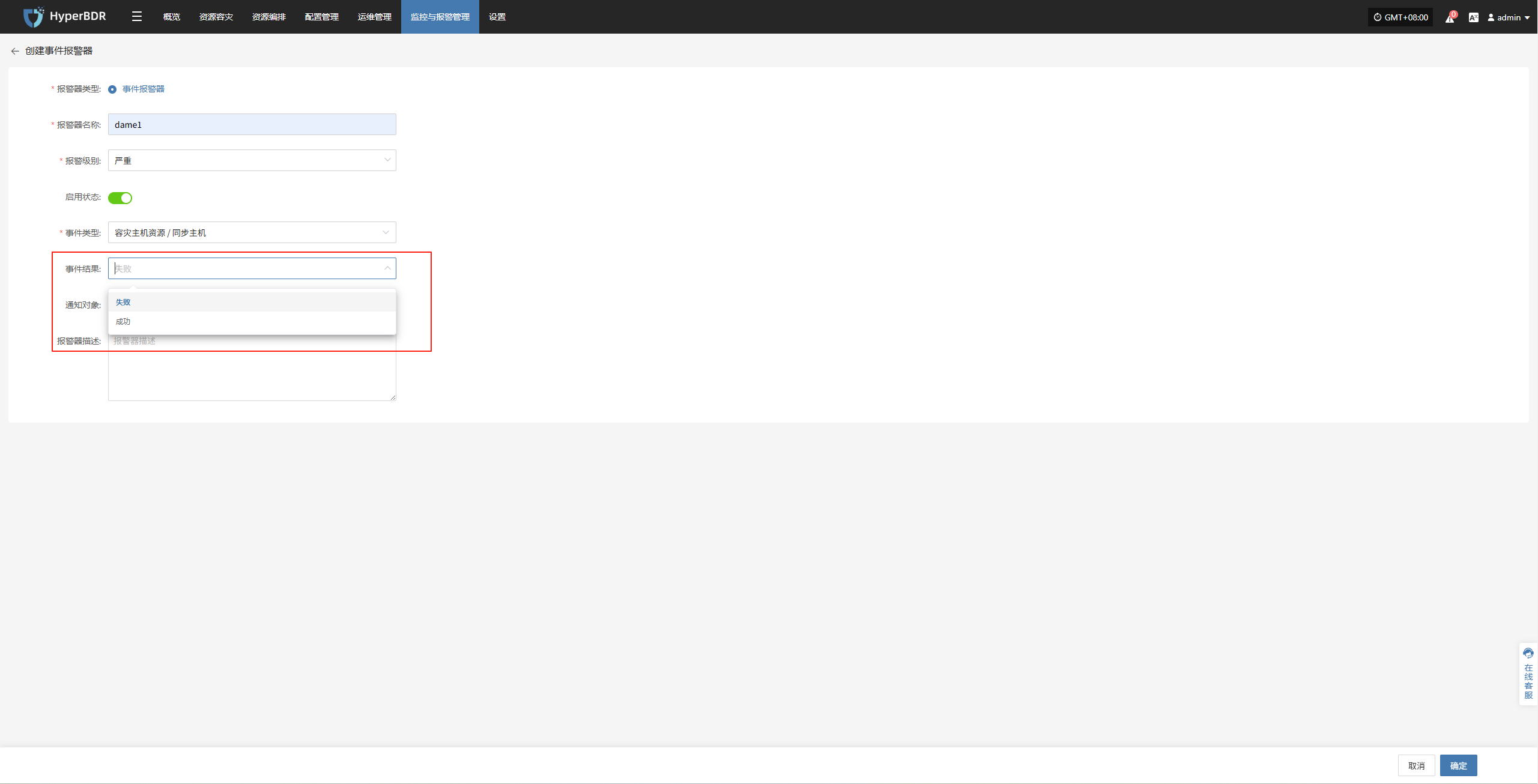
完成创建

常见使用场景
突发备份失败排查:通过监控看板查看任务日志、系统资源占用、网络状况,定位故障点。
性能瓶颈分析:根据历史指标趋势,判断是否需要增加带宽、提升服务器配置或优化备份策略。
容灾演练观察:在进行容灾演练时,通过概览实时监控恢复任务进度与资源使用情况。
容灾演练
演练准备
容灾演练是确保灾备系统真正可用的重要环节。建议每季度或至少每半年进行一次全流程演练。
演练目标与范围
明确演练要覆盖哪些业务系统、数据类型、RPO/RTO 目标。
确定演练场景:如模拟机房断电、核心网络故障、云平台区域性宕机等。
资源预留
为演练准备必要的目标环境资源(云主机、存储、网络配置等)。
确保不会影响生产业务的正常运行,可使用测试环境或预留的灾备资源。
通知与审批
提前告知相关业务方、管理层和运维团队,获取演练时间窗及授权。
制定演练脚本和回退方案,确保在意外情况下能够终止演练并恢复原状。
演练流程
触发灾难场景
人工或脚本模拟故障,例如停止源端服务器、电源中断、网络隔离等。
确认监控告警正常触发,HyperBDR 控制台是否实时显示故障信息。
启动容灾演练流程
- 在 HyperBDR 控制台选择对应的容灾主机,点击“容灾演练”,选择恢复时间点,一键恢复容灾主机到目标环境。
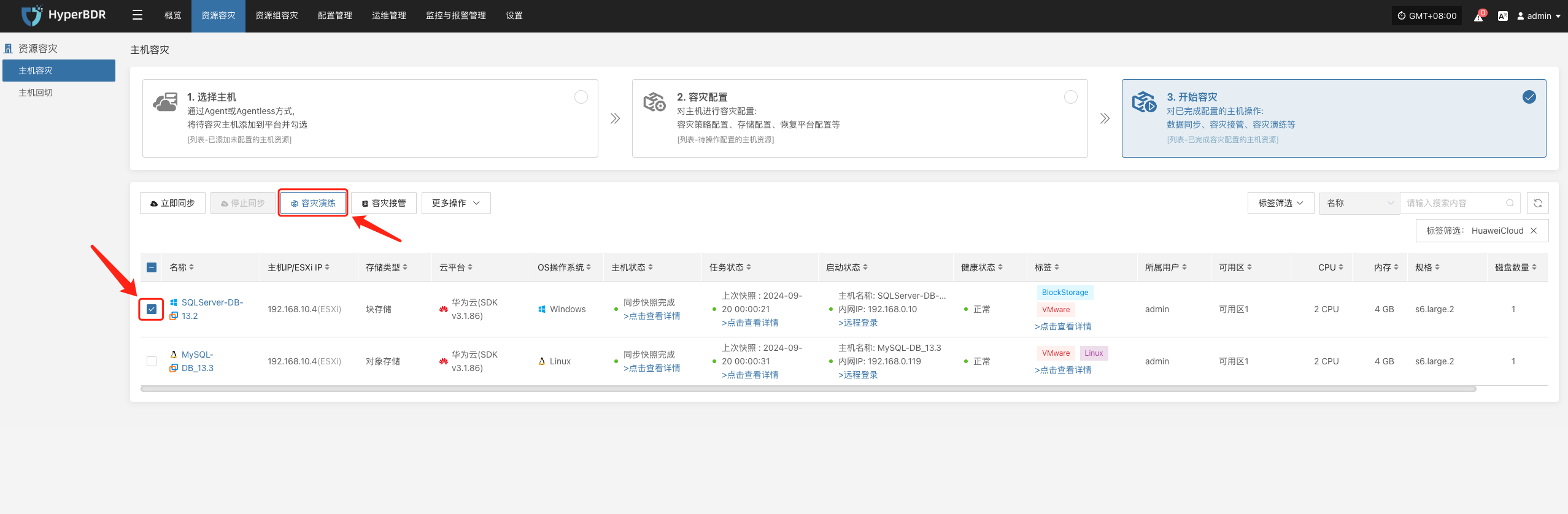

系统会根据预先配置的资源编排(计算、存储、网络等)自动化创建或启动目标端实例,等待启动完成,即可登录到目标平台进行验证配置及业务演练。
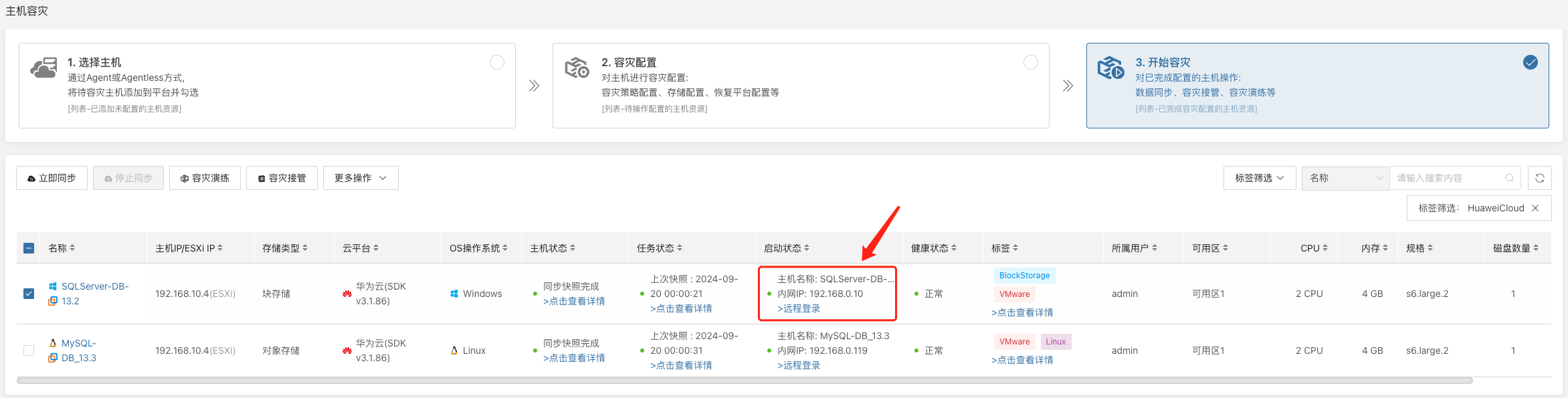
监控恢复进度,确保在预期 RTO 内完成关键业务的演练。
业务验证
恢复完成后,检查应用服务、数据库、负载均衡等是否正常工作。
执行数据一致性校验,确认业务功能完整可用。
演练验证与报告
演练结果评估
对比实际恢复时间与预设 RTO/RPO 是否达标。
统计演练过程中出现的异常、故障点及处理耗时。
演练报告编写
- 包含演练目标、执行步骤、结果分析、存在问题及改进措施。
可以通过平台侧的“报告导出”功能,选择本次演练的主机,导出主机容灾演练详细报告。
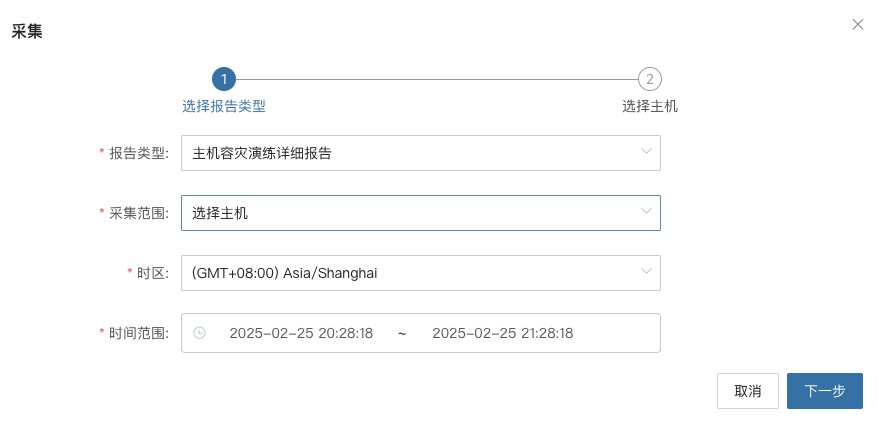
- 分发给相关团队(业务、管理层、审计),形成闭环管理。
后续优化
根据演练中发现的问题,调整备份策略、资源配置或故障流程。
更新文档与自动化脚本,提升下一次演练和真实容灾接管场景下的应对效率。
容灾接管
接管条件与前提
当源端业务发生严重故障或灾难无法迅速恢复时,需要在灾备环境进行故障接管(Failover),以保证业务连续性。
确认故障等级
若故障无法在短时间内修复,且已超出容忍的 RTO/RPO 界限,即可启动灾备接管。
需事先确认生产环境确实无法快速恢复,避免盲目接管导致更大影响。
灾备环境准备
确保目标环境已在 HyperBDR 策略中完成最新的数据同步或快照备份。
灾备环境的网络配置、资源配额已满足业务上线要求(如 CPU/内存/带宽等)。
业务影响评估
与业务方沟通,了解切换后对用户访问路径、数据一致性、应用依赖的影响。
确认接管操作窗口和是否需要对外发布公告(如对客户告知切换事宜)。
故障接管流程
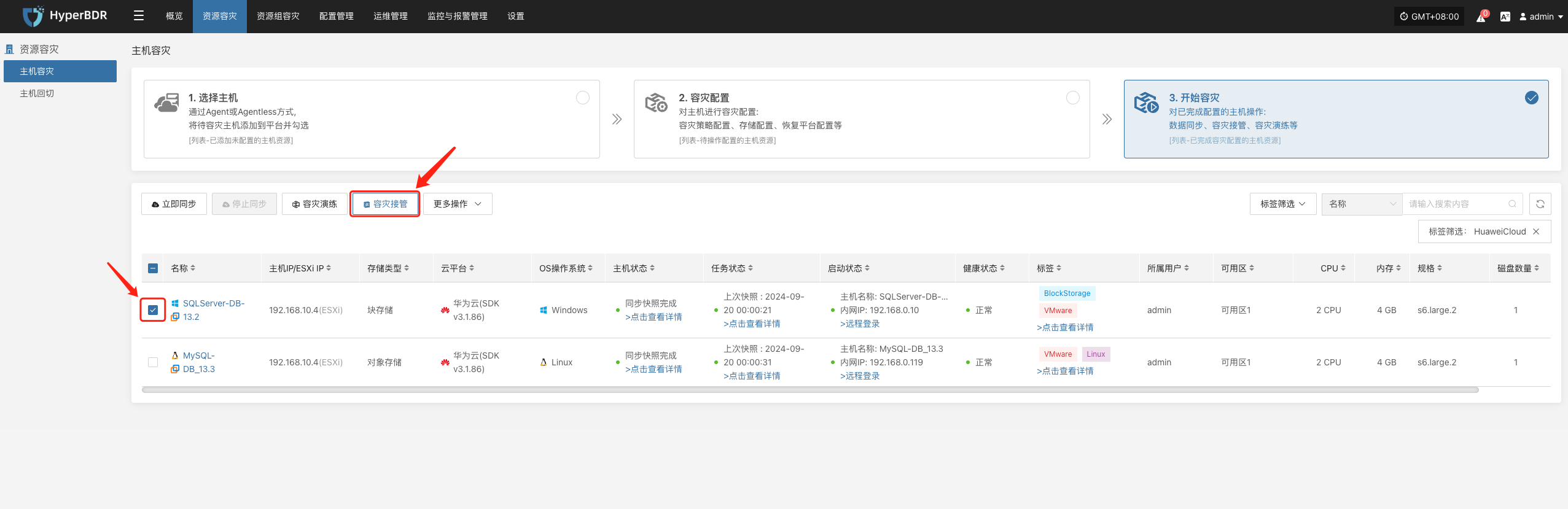
启动接管
- 在 HyperBDR 控制台选择对应业务主机的“容灾接管”功能,按照需求选择恢复快照时间点,并点击确定
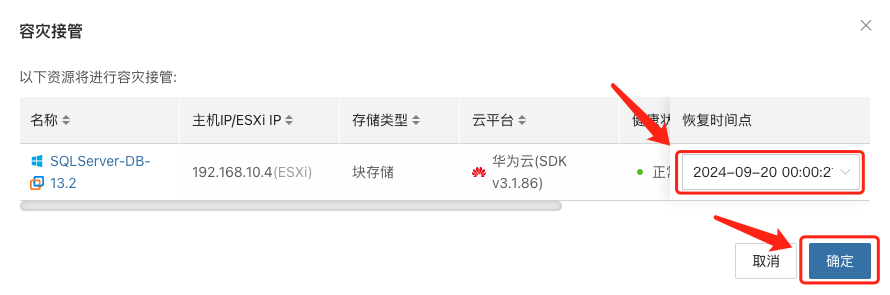
系统会根据预先配置的资源编排(计算、存储、网络等)自动化创建或启动目标端实例,等待启动完成,即可登录到目标平台进行验证配置及业务接管。
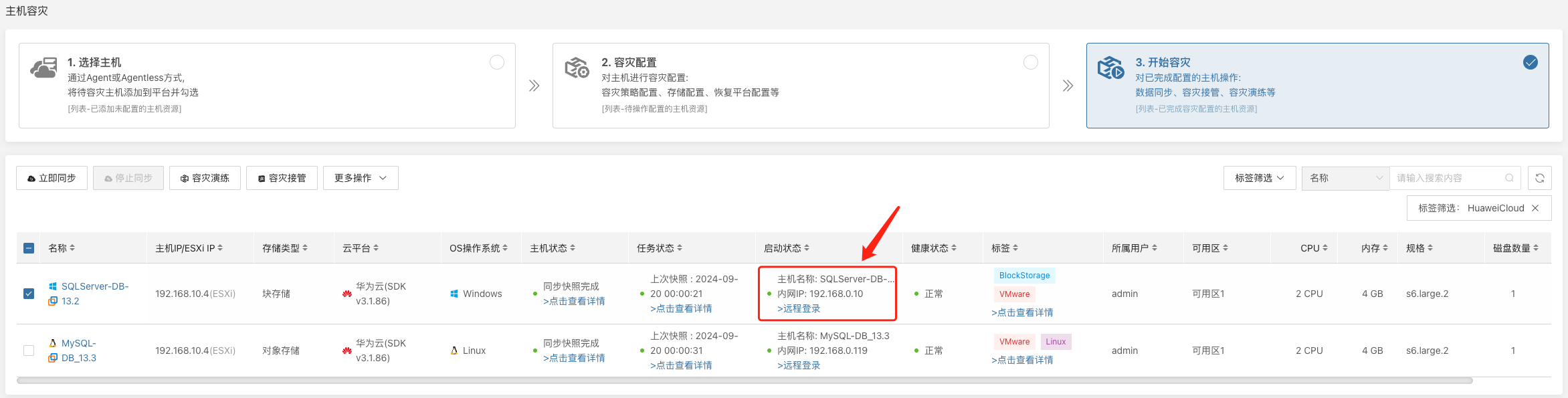
数据校验
业务启动后,检查数据库版本、应用服务配置、依赖服务(如缓存、消息队列)是否正常。
若需要,只在灾备环境中进行部分流量测试,确认业务功能可用后再全量切换。
DNS / 负载均衡切换
修改 DNS 解析或负载均衡策略,将用户流量指向灾备环境。
监控流量变化,确保接管后业务访问正常。
确认切换完成
记录接管完成时间,并在监控看板中持续观察系统指标。
与业务方沟通验证功能、性能是否达到预期。
导出业务接管报告
可以通过平台侧的“报告导出”功能,选择本次接管的主机,导出主机容灾接管详细报告。
将业务接管事件导出的报告进行留存并进一步分析,是否存在优化步骤及流程。
附录
常用命令与工具
HyperBDR
服务日志查看
后台日志组件服务目录
/opt/installer/production/logs/- 服务组件状态检查
docker ps #查看各服务模块网络排查:
ping,traceroute,telnet,curl等常见命令
常见问题查询及提交
日常运维过程中,遇到相关问题,可以访问以下QA网站进行查询问题相关解决方案。 如遇到问题,也可以登录QA网站提交遇到的问题,我们会在提交问题后第一时间进行问题的分析及快速响应。
版本变更记录
| 版本 | 日期 | 变更说明 | 作者 |
|---|---|---|---|
| 1 | 2024-08-20 | 初始版本发布 | 容灾产品运维组 |
| 2 | 2024-12-10 | 更新告警配置 | 容灾产品运维组 |
| 3 | 2025-02-10 | 增加容灾演练/接管操作 | 容灾产品运维组 |
| 4 | 2025-02-15 | 增加日志导出功能 | 容灾产品运维组 |
| 5 | 2025-02-25 | 增加常见问题说明 | 容灾产品运维组 |
结语
文档总结
本运维手册聚焦 HyperBDR 在生产环境下的 日常运营、监控看板使用、容灾演练及故障接管 关键环节,提供了系统化的操作流程与最佳实践。运维团队应定期审阅并根据实际情况对本手册进行更新,以确保 HyperBDR 系统持续稳定运行、及时满足业务的容灾与高可用需求。