HyperBDR SAP-HANA-DR 混合云容灾方案最佳实践
HyperBDR SAP-HANA-DR 混合云容灾方案最佳实践
本文档基于拉美地区电信运营商(含金融服务业务)在华为云上的真实 DR 演练项目整理,面向市场与伙伴侧,重点展示 HyperBDR 编排(Orchestration)能力在 SAP HANA 场景下的应用:编排功能统一调度 DR 接管流程,先调用 HANA Replication 恢复数据库,再调用 HyperBDR Boot in Cloud 一键拉起应用层,实现混合容灾方案。
一、项目概述
1.1 客户与场景
| 维度 | 说明 |
|---|---|
| 行业 / 区域 | 电信运营商(含金融服务业务),拉美地区(Honduras / Costa Rica) |
| 业务特点 | 核心业务包括计费与信贷、销售点交易(POS)、文档管理(OnBase)等,涉及金融性交易与客户身份验证 |
| 关键系统 | SAP(S/4HANA 核心事务、CAR 客户活动分析、HPI 报表)、POS 销售点系统、OnBase 文档流程、MongoDB 等 |
| 业务系统规模 | 50 台主机,存储量约 50 多 TB |
| 源端环境 | VMware 虚拟化环境,生产环境在本地 |
| 容灾目标 | 灾备环境在华为云;演练验证 RPO/RTO,确保计费、信贷等金融性业务在灾备切换时能够受控、及时、一致地恢复,且不影响生产 |
本项目是典型的 SAP HANA 容灾(DR)场景:以 SAP 为核心,配套计费、信贷、销售点等金融性业务系统,通过 HyperBDR 容灾与编排能力实现云端灾备。此类场景对数据一致性与恢复时间要求极高,适合作为金融/电信行业 SAP 容灾的参考案例。
1.2 HyperBDR 在本项目中的核心价值
编排能力为本文档最突出的要点:接管流程由 HyperBDR 编排(Orchestration)统一调度——先调用 HANA Replication 恢复数据库,再调用 HyperBDR Boot in Cloud 一键拉起应用层主机(含 SLT 等 50 台),实现受控、有序的 DR 接管。
混合容灾方案:通过编排串联 SAP HANA Replication 与 HyperBDR,实现“数据库级实时复制 + 整机级编排恢复”的混合容灾架构,兼顾 RPO/RTO 要求与成本效益。
对象存储技术:采用对象存储(OBS)作为中间存储层,降低目标端使用成本,并通过 boot in cloud 一键拉起在云上把完整业务系统拉起,这是 HyperBDR 的特色能力。
无代理方式:本项目主要采用 VM 无代理方式(源端为 VMware),无需在源端安装代理,降低部署复杂度与运维负担。
二、业务挑战与 HyperBDR 的应对
SAP HANA 容灾往往面临以下挑战,本项目通过 HyperBDR 容灾与编排能力提供解决方案:
| 挑战 | 说明 | HyperBDR 的应对 |
|---|---|---|
| 系统复杂度 | SAP 与 SLT、CAR、HPI 及周边应用(POS 销售点、OnBase 文档、MongoDB)存在强依赖,切换需协同;金融性业务对数据一致性要求极高;50 台主机、50 多 TB 存储的规模增加了编排复杂度 | HyperBDR 的编排能力支持 50 台主机通过 boot in cloud 一键拉起并行恢复与依赖管理,通过固定时间线与责任人,确保计费与信贷数据在切换过程中保持一致 |
| RPO/RTO 要求高 | 计费、信贷等金融性交易与分析不允许长时间中断或大量数据丢失;客户身份验证(如 Valkiria 身份证查询)需实时可用 | 编排驱动接管:编排先调用 HANA Replication 实现 SAP HANA 层面 RPO≈0、RTO<5 min,再调用 Boot in Cloud 快速恢复应用层 VM,整体 RTO 控制在 2 小时内 |
| 目标端成本 | 传统容灾方案在目标端需要大量存储资源,成本较高 | 对象存储技术:HyperBDR 通过对象存储(OBS)作为中间存储层,降低目标端使用成本,并通过 boot in cloud 一键拉起在云上把完整业务系统拉起,这是 HyperBDR 的特色能力 |
| 带宽与同步 | SLT 及演练后再同步受带宽制约,影响恢复时间 | HyperBDR 支持策略化同步(周期/策略同步),可与 HANA Replication 带宽需求协调,优先保障关键复制链路 |
| 部署与运维复杂度 | 传统容灾方案需要在源端安装代理,增加部署与运维负担 | 无代理方式:HyperBDR 采用 VM 无代理方式,无需在源端安装代理,降低部署复杂度与运维负担 |
这些挑战在多数 SAP 上云容灾场景中具有共性,因此本项目展示的 HyperBDR 容灾与编排能力具有可复用的最佳实践价值。
三、HyperBDR 方案与架构
3.1 总体思路:编排驱动的接管流程
HyperBDR 编排(Orchestration)是接管流程的核心驱动力,统一调度各恢复动作:
编排先调用 HANA Replication:恢复 SAP HANA 数据库(本地 → 华为云),实现数据库层面 RPO≈0、RTO<5 min。
编排再调用 HyperBDR Boot in Cloud:一键拉起应用层主机(含 SLT 等 50 台,存储量约 50 多 TB),关键应用在 9 min–2 h 内就绪;采用对象存储(OBS)降低目标端成本,无代理方式降低部署复杂度。
编排按顺序调度 HANA Replication 与 Boot in Cloud,形成“数据库级 + 整机级”双重保障,兼顾性能与成本。
3.2 架构要点
生产端(VMware):SAP HANA(S/4、CAR)、SLT、POS、OnBase 等部署在客户本地 VMware 环境。
灾备端(华为云):
HANA 次要节点(通过 HANA Replication 实时复制)
应用层主机(含 SLT 等 50 台主机,由 HyperBDR 编排在 HANA 恢复后调用 Boot in Cloud 一键拉起)
存储层:对象存储(OBS)作为中间存储层(约 50 多 TB),降低目标端使用成本,支持 boot in cloud 一键拉起在云上把完整业务系统拉起。
复制关系:
HANA Replication(实时,数据库级)
HyperBDR(周期/策略同步,整机级,通过 OBS)
下图为本项目的高层架构,展示了 HyperBDR 编排驱动接管(先 HANA Replication,再 Boot in Cloud)的混合容灾方案:
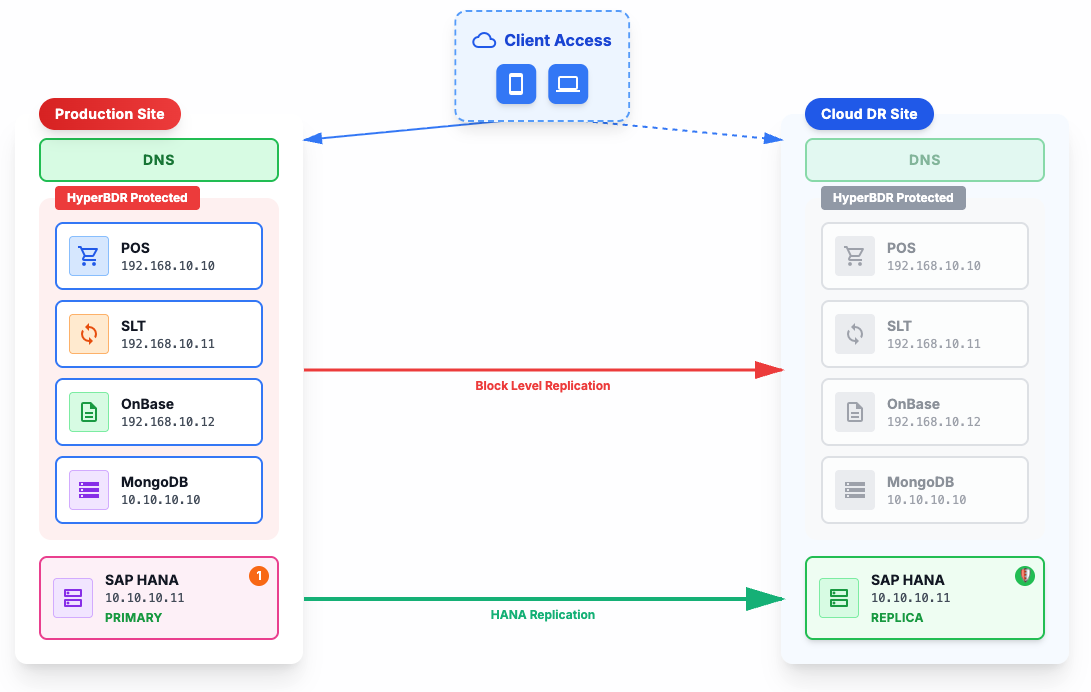
图 1 高层架构:HANA Replication + HyperBDR 混合容灾方案
3.3 HyperBDR 核心能力在本项目中的体现
| HyperBDR 能力 | 在本项目中的应用 | 价值 |
|---|---|---|
| 编排能力(Orchestration) | 接管流程由编排统一调度:先调用 HANA Replication 恢复数据库,再调用 Boot in Cloud 一键拉起 50 台应用层主机,并行恢复与依赖管理,关键应用 9 min–2 h 内就绪 | 本方案最突出的要点:编排作为核心驱动力,实现受控、有序的 DR 接管 |
| boot in cloud 一键拉起 | 通过 OBS 作为中间存储层(约 50 多 TB),降低目标端使用成本,boot in cloud 一键拉起在云上把完整业务系统拉起 | 降低目标端存储成本,提升容灾方案的经济性;boot in cloud 一键拉起能力是 HyperBDR 的核心特色 |
| 无代理方式 | VM 无代理方式,无需在源端安装代理 | 降低部署复杂度与运维负担,提升客户接受度 |
| 策略化同步 | 支持周期/策略同步,可与 HANA Replication 带宽需求协调 | 灵活应对不同 RPO/RTO 要求,优化带宽使用 |
四、实施要点与演练最佳实践
4.1 数据复制阶段
在演练前的数据复制阶段,本项目采用混合复制策略:
SAP HANA 数据库复制:通过 SAP HANA Replication 实现数据库级的实时复制,从生产端 SAP HANA 复制到灾备端 SAP HANA,确保数据库层面 RPO≈0。
应用主机复制:通过 HyperBDR 实现主机级的块存储复制,将生产端约 50 台主机(含 SLT、POS、OnBase、MongoDB 等应用系统)的数据复制到对象存储(OBS),降低目标端存储成本。
关键主机复制策略:对于约 26 台关键应用主机(如 SLT、核心 SAP 应用等),采用 15 分钟复制一次的频率,确保关键业务系统的 RPO 更小,数据丢失风险更低。
其他主机复制策略:对于其余约 24 台主机,采用 3 小时复制一次的频率,在保障数据安全的同时优化带宽使用和存储成本。
数据复制过程是持续进行的,为后续演练和接管提供数据基础。HyperBDR 的策略化同步能力支持根据业务重要性灵活配置不同主机的复制频率,实现 RPO 要求与成本效益的平衡。
4.2 演练与接管阶段最佳实践
演练和接管是验证容灾方案有效性的关键环节。本项目采用HyperBDR 编排(Orchestration)驱动的接管流程,以下是演练过程中的详细步骤和最佳实践:
4.2.1 演练前准备:模拟停止生产业务同步
在演练开始前,需要模拟真实灾难场景下的同步切断过程,确保演练不影响生产环境。本项目的演练前准备包括:
| 步骤 | 时间 | 关键动作 | 目的 |
|---|---|---|---|
| SLT 同步对齐 | 演练前约 3 小时 | HyperBDR 中 SLT 自动/手动同步,确保数据对齐 | 在切断前完成最后的数据同步,减少数据丢失 |
| 停止 SLT 复制 | 演练前约 3 小时 | 在源端(Tigo)停止 SLT,受控停止复制 | 模拟生产环境停止,切断前对齐 CAR 同步 |
| 停止 HyperBDR 同步 | 演练前约 2.5 小时 | 停止 HyperBDR 中全部 VM(约 50 台主机)的同步 | 模拟同步切断,降低带宽需求;这是真实接管时的常规流程(完全切断) |
| 停止次要实例通信 | 演练前约 15 分钟 | 停止次要 SAP HANA 实例通信,保持 DR 隔离 | 确保 DR 环境与生产环境隔离,HyperBDR 代理保持通信但处于非活动状态 |
演练前准备的关键要点:
演练前准备步骤仅在测试场景(演练)前执行,在真实接管中可能有所不同
受控停止同步确保数据完整性,避免演练过程中生产数据继续变化
通过模拟切断验证容灾方案在真实灾难场景下的有效性
4.2.2 演练与接管阶段
| 阶段 | 目标 | 详细步骤与 HyperBDR 关键动作 | 时间与结果 |
|---|---|---|---|
| 阶段 1:接管启动 | 数据库恢复正常 | 1. 编排先调用 HANA Replication 接管 SAP HANA 数据库 - CAR 数据库接管:20 秒 - 修改 hosts 文件:6 分钟 - S4 数据库接管:1 分 20 秒 2. 在华为云启动 SLT:48 分钟 3. 验证数据库连接和状态 | • SAP HANA 接管总时间:< 5 分钟 • SAP HANA 就绪:接管后约 5 分钟内 • SLT 就绪:48 分钟 |
| 阶段 2:基础设施拉起 | 应用与依赖就绪 | 1. 编排再调用 Boot in Cloud 一键拉起应用层主机 2. 通过 HyperBDR 创建实例:演练中创建约 30 台 VM(总保护 50 台主机) - 创建时间:9 分钟至 2 小时 03 分钟 - 关键应用:POS、SAP HPI 3. 初始配置与 hosts 文件调整:20 分钟 4. 应用初步功能验证:随 VM 逐步可用而渐进测试 | • 关键应用创建时间:9 分钟至 2 小时 03 分钟 • POS 基础设施:< 2 小时 30 分钟 • OnBase 基础设施:约 3 小时 40 分钟 |
| 阶段 3:DR 运行验证 | 业务与稳定性验证 | 1. 验证通过 boot in cloud 一键拉起恢复的 VM 功能 2. 测试应用层功能(POS、OnBase、MongoDB 等) 3. SAP Router (EIP) 测试:从云访问验证成功 4. 验证业务连续性(计费、信贷等金融性业务) 5. 监控系统稳定性和性能 | • 应用服务器运行稳定,响应时间在正常预期范围 • Active Directory 在华为云上成功验证并可访问 • POS MongoDB:部分节点就绪 |
| 阶段 4:收尾与再同步 | 恢复生产复制、无残留 | 1. 停止次要 SAP HANA,开始配置以实现快速再同步 2. DR VM 关机与删除:受控清理 3. 恢复 VPN:成功恢复连通性 4. HANA Replication 再同步: - CAR 再同步:约 12 小时 - S4 再同步:约 12 小时(带宽优化后) 5. HyperBDR 复制恢复,重新建立主机级复制 6. 带宽优化:从 200 Mbps 提升至 400 Mbps | • CAR 再同步:约 12 小时 • S4 再同步(优化前):超过 48 小时(因带宽限制失败) • S4 再同步(优化后):约 12 小时 • 演练后恢复时间(优化后):< 19 小时 |
演练过程中的 HyperBDR 最佳实践要点:
编排驱动接管:HyperBDR 编排(Orchestration)统一调度整个接管流程——先调用 HANA Replication 恢复数据库,再调用 Boot in Cloud 一键拉起应用层主机。编排确保恢复顺序正确,避免应用在数据库未就绪时启动,造成连接失败。
并行恢复与依赖管理:HyperBDR 的编排能力支持多 VM 通过 boot in cloud 一键拉起并行恢复,同时管理应用间的依赖关系。关键应用优先启动,缩短整体恢复时间,50 台主机可在 2 小时内完成恢复。
boot in cloud 一键拉起:通过 OBS 作为中间存储层,降低目标端使用成本,并通过 boot in cloud 一键拉起在云上把完整业务系统(50 台主机、50 多 TB 存储)拉起,这是 HyperBDR 的核心特色能力。
带宽与优先级协调:演练后再同步时,HyperBDR 的策略化同步可与 HANA Replication 带宽需求协调,优先保障关键复制链路。本项目通过带宽优化(200→400 Mbps),演练后恢复时间从约 48 小时缩短至 <19 小时。
五、关键成果与指标
采用 HyperBDR 编排驱动的混合容灾方案,在 DR 演练及接管过程中可达到以下效果,体现 HyperBDR 容灾与编排能力在 SAP HANA 场景下的可度量成果:
| 指标 | 结果 | HyperBDR 的贡献 |
|---|---|---|
| SAP HANA 接管 | RTO < 5 分钟,RPO ≈ 0 | HANA Replication(数据库级) |
| SAP HANA 就绪 | 接管后约 5 分钟内 | HANA Replication |
| SLT 就绪 | 48 分钟 | HyperBDR boot in cloud 一键拉起 SLT |
| 应用层就绪 | 关键应用创建时间:9 分钟至 2 小时 03 分钟 | HyperBDR boot in cloud 一键拉起应用层主机(演练中创建约 30 台 VM,总保护 50 台主机) |
| 基础设施(POS) | < 2 小时 30 分钟 | HyperBDR boot in cloud 一键拉起 POS 相关 VM |
| 基础设施(OnBase) | 约 3 小时 40 分钟 | HyperBDR boot in cloud 一键拉起 OnBase VM |
| 演练后恢复时间(优化前) | 约 48 小时(带宽 200 Mbps) | HyperBDR 策略化同步 + HANA Replication 协调 |
| 演练后恢复时间(优化后) | < 19 小时(带宽优化至 400 Mbps 后) | HyperBDR 策略化同步 + HANA Replication 协调 |
说明:不同环境与带宽条件下数值会有差异,但HyperBDR 编排驱动的混合容灾架构具备可复制性。
六、项目总结
本项目成功验证了 HyperBDR 容灾与编排能力在 SAP HANA 场景下的有效性,为拉美地区电信运营商(含金融服务业务)实现了云端容灾方案。项目取得的关键成果如下:
6.1 关键成果
SAP HANA 数据库接管:RTO < 5 分钟,RPO ≈ 0,通过 HANA Replication 实现数据库级实时复制
应用层快速恢复:50 台主机通过 HyperBDR boot in cloud 一键拉起,关键应用在 9 分钟至 2 小时 03 分钟内就绪
混合容灾架构验证:成功验证"数据库级实时复制 + 整机级编排恢复"的混合容灾方案,编排能力统一调度整个接管流程
成本优化:通过对象存储(OBS)技术降低目标端存储成本,50 多 TB 存储采用对象存储方案,显著提升容灾方案的经济性
无代理部署:采用 VM 无代理方式(源端为 VMware),降低部署复杂度与运维负担
6.2 项目价值
本项目展示了 HyperBDR 编排(Orchestration)能力在复杂 SAP HANA 容灾场景下的核心价值:
编排驱动接管:HyperBDR 编排统一调度 DR 接管流程,先调用 HANA Replication 恢复数据库,再调用 Boot in Cloud 一键拉起应用层主机,实现受控、有序的接管,整体 RTO 控制在 2 小时内
混合容灾方案:通过编排串联 SAP HANA Replication 与 HyperBDR,实现"数据库级实时复制 + 整机级编排恢复"的混合容灾架构,兼顾 RPO/RTO 要求与成本效益
boot in cloud 一键拉起:通过 OBS 作为中间存储层,降低目标端使用成本,并通过 boot in cloud 一键拉起在云上把完整业务系统(50 台主机、50 多 TB 存储)拉起,这是 HyperBDR 的核心特色能力
策略化同步:支持根据业务重要性灵活配置复制频率(关键主机 15 分钟,其他主机 3 小时),实现 RPO 要求与成本效益的平衡
6.3 典型场景
本项目覆盖了SAP S/4HANA + CAR + HPI + 周边应用(POS、OnBase、MongoDB)的典型组合,特别是金融/电信行业中"计费与信贷 + SAP 核心系统"的容灾场景。项目验证了 HyperBDR 在 50 台主机、50 多 TB 存储规模下的容灾能力,对同类客户具有代表性和参考价值。