Data Sync Fundamentals
Data Sync Fundamentals
This document aims to provide a detailed explanation of the source-side synchronization principle, covering the underlying implementation technologies of both Agent-based and Agentless modes. As one of the core technologies for data backup and recovery solutions, the efficiency and reliability of source-side synchronization directly impact the overall performance of disaster recovery systems. This document will focus on the core implementation mechanisms of our product in these two modes and provide an in-depth explanation of the incremental data acquisition principle, helping readers gain a comprehensive understanding of the key technologies behind data synchronization.
Data Consistency and Recoverability Design
1. Design Philosophy and Principles
In disaster recovery, data consistency is not the end goal. The core measure of a disaster recovery solution's effectiveness is whether business systems can be successfully recovered and run stably after a disaster.
The product follows a "recovery-centric, consistency-based" approach. This principle emphasizes:
- Data consistency is necessary but not sufficient for disaster recovery
- Theoretical "consistency guarantees" must be confirmed through actual recovery validation
- Disaster recovery capabilities should be based on engineering validation results, not just assumptions about sync mechanisms or consistency models
Following this philosophy, the product strictly adheres to native data capture and snapshot mechanisms provided by operating systems, databases, and cloud platforms during data acquisition, avoiding non-standard or highly invasive data control methods. On the disaster recovery side, it uses periodic, repeatable disaster recovery drills to continuously validate data recoverability and business system operability, treating drill results as the final criteria for assessing disaster recovery effectiveness.
2. Disaster Recovery Drills and Data Integrity Validation
The product treats disaster recovery drills as a fundamental capability, not an optional feature in the disaster recovery system.
The system provides complete disaster recovery drill mechanisms to periodically validate the availability of disaster recovery data under real recovery paths. Drills typically include:
- Starting complete business systems or database instances in the disaster recovery environment
- Executing native recovery processes supported by the operating system or database
- Verifying that systems can start normally, data is accessible, and core business services are operational
By conducting drills in isolated environments that don't affect production systems, the product can identify potential issues early, such as:
- Incomplete database logs or sequence anomalies
- Operating system startup failures
- Missing services, configurations, or components required for application operation
These issues can be identified and fixed before real disasters occur, significantly reducing recovery risks. In the product's design, drill results themselves constitute the final validation standard for data integrity and recoverability.
3. Data Capture Methods and Consistency Strategies
The product provides differentiated data consistency strategies based on operating system types and deployment modes to match the actual operational characteristics of different business systems.
- Windows Agent Mode
On Windows platforms, the product agent integrates with the system's built-in Volume Shadow Copy Service (VSS):
For applications or databases that support this mechanism
- Coordinates I/O freeze and cache flush before data capture
- Obtains application-consistent data state
When target systems or applications don't provide relevant interfaces
- Data consistency level automatically falls back to crash consistency
This mode suits business systems with high application or database consistency requirements.
- Linux Agent Mode
Since Linux lacks a unified application consistency coordination interface, the product provides file system consistency data protection in Linux environments:
- Data state is equivalent to disk state after an abnormal operating system restart
- The system doesn't force intervention in database transactions or application internal logic
- Data recovery relies on the database's own log mechanisms and self-recovery capabilities
In this mode, the product's core responsibility is to provide a stable, repeatable data baseline and validate through disaster recovery drills whether databases or applications can complete their native recovery processes.
- Agentless Mode
In cloud or virtualization platforms, the product's agentless mode captures data based on platform-native disk snapshot capabilities:
- Provides crash-consistent data state
- No components need to be deployed inside virtual machines
- No interaction with operating systems or applications
This mode offers high compatibility and low invasiveness, suitable for rapid deployment in large-scale environments. For agentless mode, the product explicitly recommends combining regular disaster recovery drills to validate the actual recoverability of business systems in the disaster recovery environment.
4. Database Scenario Applicability
For database systems that rely on logs for recovery, successful recovery depends heavily on log completeness and consistency.
In database scenarios, the product's technical positioning is as follows:
- Does not replace native database backup or archiving mechanisms
- Does not promise fully automated, zero manual intervention database recovery
- Does not support specific cluster or special storage architecture database deployment modes
The product's core value lies in: validating through disaster recovery drills whether database instances can successfully complete recovery following their native startup and recovery paths. Only database recovery results validated through drills are considered disaster recovery data with actual business availability.
Summary
The product does not equate disaster recovery capabilities with any single consistency model. Instead, it builds a data protection and recovery system centered on engineering validation:
- On the data source side, follows native mechanisms of operating systems, databases, and platforms for data capture
- On the disaster recovery side, validates actual data recoverability through continuous, repeatable disaster recovery drills
- Uses actual recovery results as the final standard for assessing data integrity and disaster recovery capabilities
This design approach not only improves overall system stability but also effectively reduces uncertainty risks faced during actual implementation of disaster recovery solutions.
Data Sync Fundamentals
Linux Agent
The Linux Agent consists of user-space and kernel-space modules. The kernel-space module captures I/O changes and monitors read and write operations in the file system. The user-space module transfers the captured data to the target storage using different protocols and manages the process of full and incremental backups. Through the collaboration of the kernel-space and user-space modules, the Linux Agent efficiently performs data synchronization and backup tasks.
The kernel module manages snapshots and tracks changes using a copy-on-write (COW) system. When first initialized, it creates a COW datastore file on the drive and intercepts writes at the block level. Before completing a write, it copies data that is about to be changed into the snapshot store, maintaining a consistent snapshot of the filesystem even during ongoing writes. The module uses an index at the start of the on-disk COW file to manage and access snapshot data, enabling reliable, consistent point-in-time block-level images that are more dependable than alternative methods.
Windows Agent
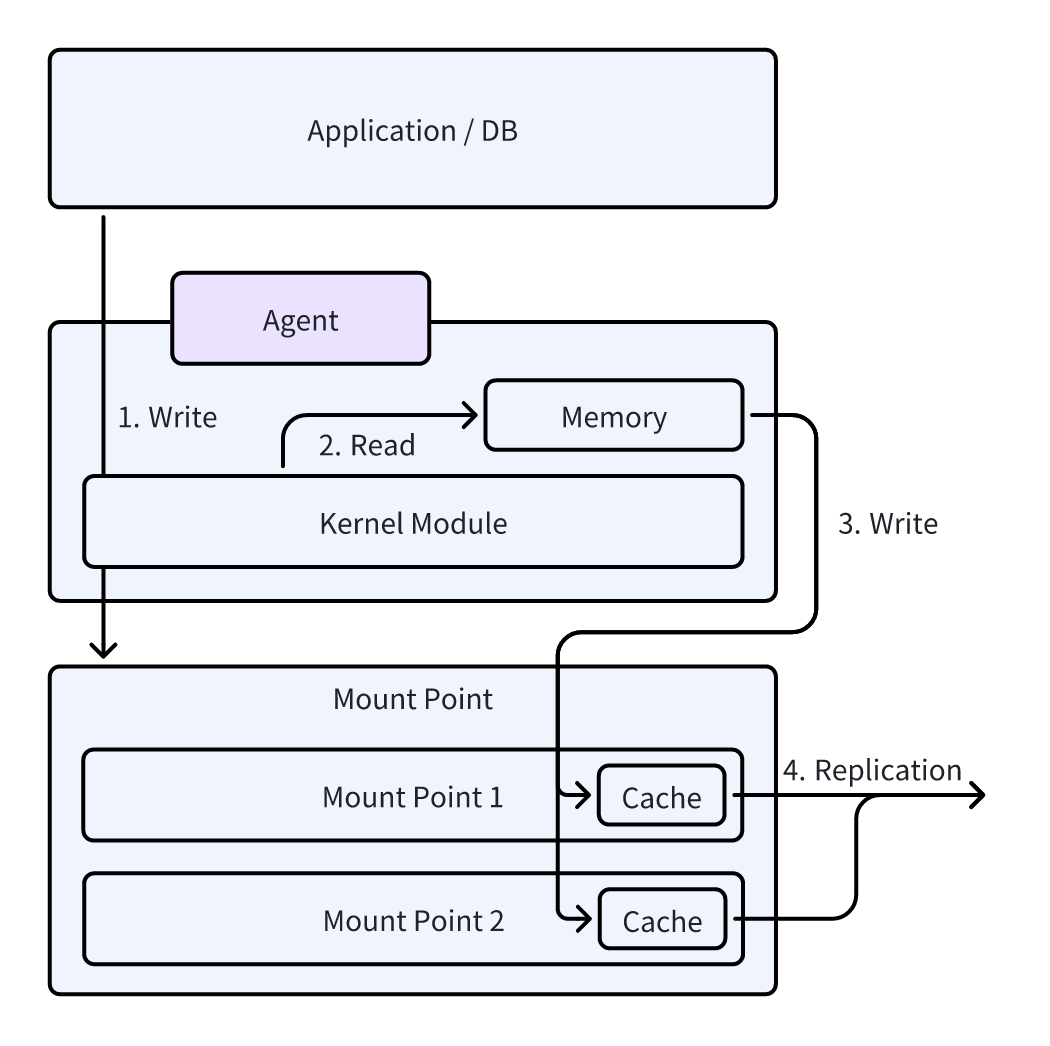
Windows Agent is divided into two main layers: kernel mode and application layer.
Kernel Mode Driver: This layer collects all write I/O operations from protected disks and provides an interface for the application layer. By using two timestamps, the kernel driver can keep track of all write I/O sequences.
Application Layer: This layer is responsible for reading disk block data and writing target data (such as via iSCSI or OSS). To improve data synchronization efficiency and ensure consistency, the application layer uses Microsoft's Volume Shadow Copy Service (VSS) technology. VSS allows for creating volume snapshots and maintains snapshot data consistency through a copy-on-write (COW) method.
Snapshots and Synchronization: Data synchronization is done at the block level. The application layer analyzes each protected disk to identify the start and end positions of each volume and creates a mapping. This helps the system quickly locate and read each block of data from the corresponding volume or disk.
Efficient Data Synchronization: To enhance synchronization efficiency, the application layer only synchronizes valid data from the volumes. It reads the metadata of each volume to check a bitmap that shows which sectors contain valid data and which do not. During data synchronization, the system skips invalid data areas to optimize the process.
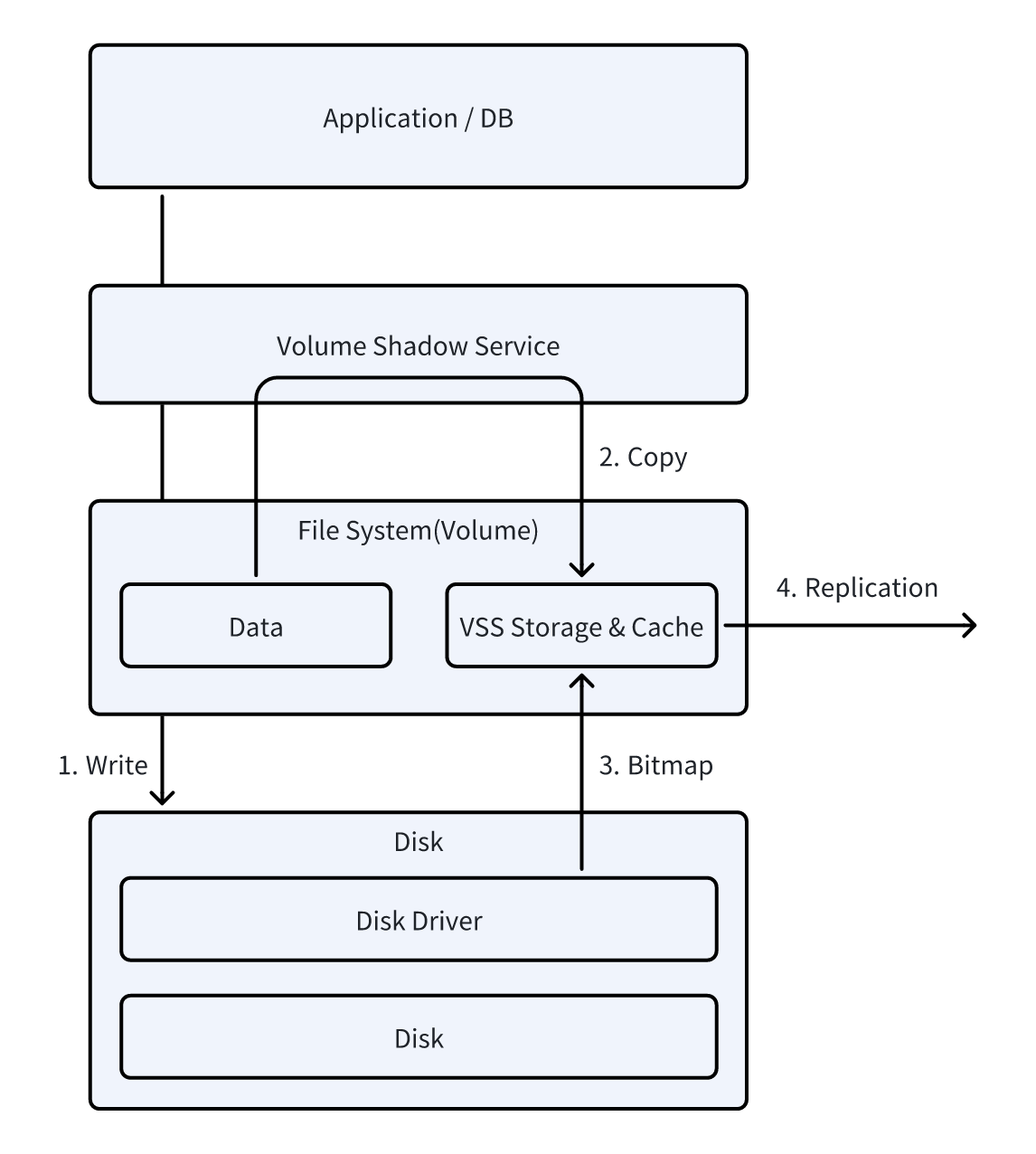
VMware Agentless
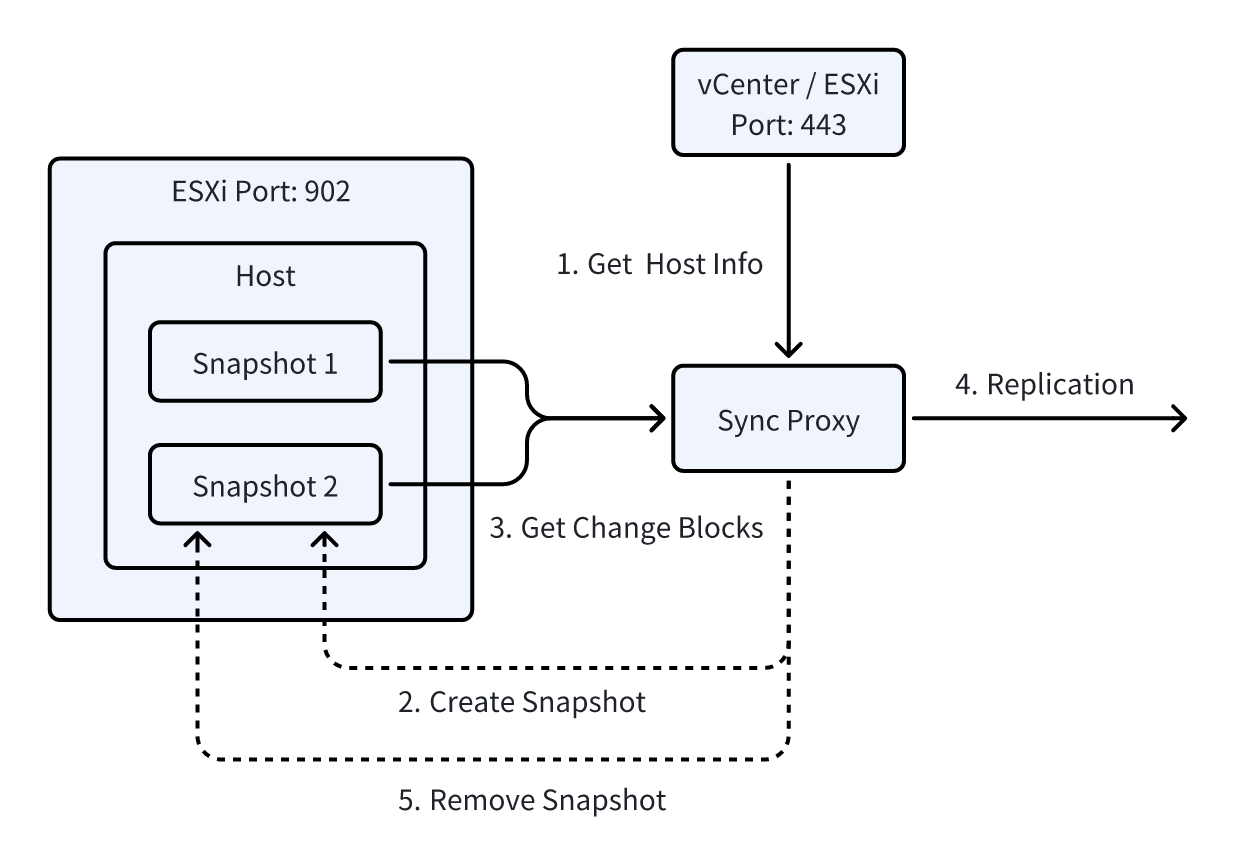
VMware agentless data synchronization is primarily achieved through VMware's Changed Block Tracking (CBT) technology. CBT is an efficient virtual machine disk change tracking technology that identifies and captures disk data blocks that have changed since the last synchronization during incremental sync. This ensures that only the changed data is synchronized, significantly improving backup efficiency.
Through the vCenter API or ESXi API, the system can access host metadata, such as virtual machine configuration, disk information, and VM power state. This allows centralized management of virtual machines across all platforms without the need to install agents on each host, preparing for subsequent data synchronization.
Before each synchronization, to ensure data consistency and integrity, the system must first call the host snapshot interface to create a virtual machine snapshot. This step ensures that disk data remains consistent during synchronization, preventing data inconsistency caused by changes to the virtual machine during the sync process.
During incremental backups, the CBT mechanism marks modified data blocks (Changed Blocks) on the disk. This allows the system to efficiently identify and sync only the changed data, without retransmitting the entire virtual machine disk content. This not only saves bandwidth and storage space but also significantly reduces the time required for backups.
OpenStack Ceph Agentless
In agentless mode, data synchronization for an OpenStack cloud platform based on Ceph storage relies on the cooperation between the source sync proxy node, Ceph storage, and OpenStack API interfaces. This synchronization method uses incremental snapshot technology to ensure an efficient data synchronization process with optimized bandwidth utilization. Below is a detailed description of this data synchronization principle:
Note: Currently, this synchronization method is only applicable to OpenStack platforms using Ceph storage with RBD connection support, and no modifications are made to the OpenStack API. This mode does not support OpenStack platforms using commercial storage solutions at this time.
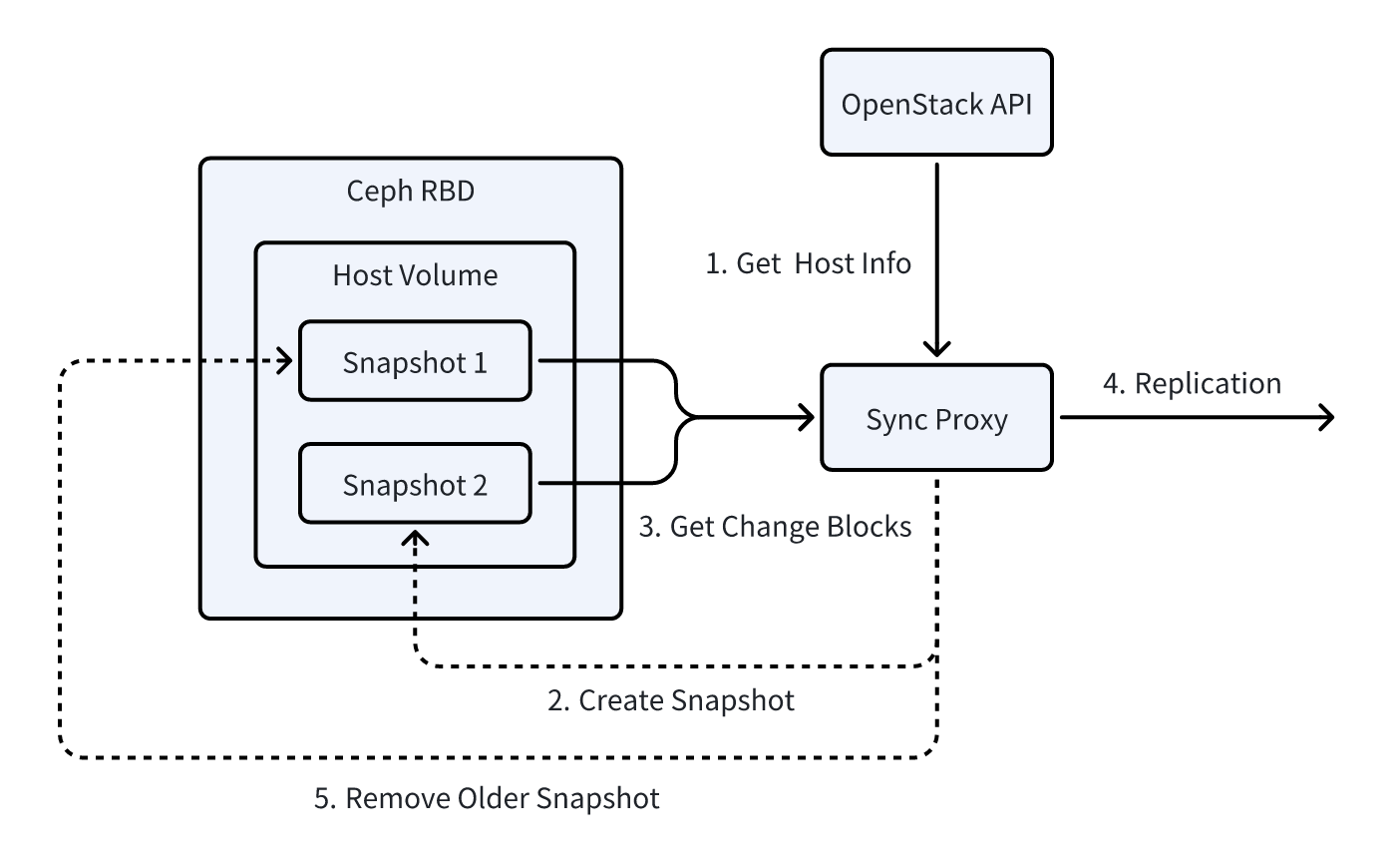
- Source Sync Proxy Node
The source sync proxy node needs to have the following two access capabilities:
- OpenStack API Access: Used to retrieve the status information of OpenStack virtual machines, perform snapshot operations on virtual machine instances, and query other related virtual machine details.
- Ceph Storage Network Access: Used to read metadata from Ceph storage pools, particularly incremental data from Ceph snapshots, to identify and synchronize changed data blocks through differential comparison.
The source sync proxy node obtains the status information of virtual machines via the OpenStack API and triggers snapshot operations. It also needs to access the Ceph storage network to obtain metadata associated with the snapshot (including block device version information, modification timestamps, etc.), enabling incremental data comparison and synchronization.
- Snapshot Operation
During incremental synchronization, the source sync proxy node first triggers a snapshot operation on the target virtual machine via the OpenStack API, generating a complete data snapshot of the virtual machine's current state. The system then calls the Ceph RBD interface to obtain the metadata of the Ceph snapshot corresponding to this snapshot. Using this metadata, the system identifies which data blocks have changed since the previous snapshot.
- Differential Data Comparison
After obtaining the metadata of the current and previous snapshots, the system compares their differences to identify the changed data blocks. The differential comparison process relies on Ceph's incremental snapshot mechanism, with the system using version information, modification timestamps, and other metadata features to precisely identify the data blocks that need to be synchronized. Once the changed data blocks are identified, the source synchronization node reads the content of these blocks from the Ceph storage network and prepares them for synchronization to the target storage.
- Data Synchronization to Target Storage
Once the changed data blocks are identified, the source sync proxy node synchronizes these differential data blocks to the target storage. By using incremental synchronization, only the changed data is synchronized, significantly reducing bandwidth requirements and minimizing unnecessary storage usage. This approach ensures the efficiency of data synchronization while minimizing resource consumption.
- Snapshot Cleanup
After data synchronization is completed, the source synchronization node performs a snapshot cleanup operation. Specifically, it deletes the previous snapshot and retains the current snapshot for the next differential data comparison. This operation helps effectively release storage space while ensuring the continuity and consistency of the synchronization process, avoiding redundant storage and unnecessary resource usage.
AWS Agentless
The advantage of AWS EC2's agentless synchronization mode mainly comes from the AWS cloud platform's AWS EBS Direct API. This technology allows users to back up and synchronize EC2 instances efficiently without installing any agents. The AWS EBS Direct API is similar in principle and mechanism to VMware CBT (Changed Block Tracking), but it provides an interface through a REST API, making it easier to integrate. Compared to traditional agent-based methods, the agentless backup mode of the EBS Direct API significantly reduces complexity and improves backup performance.
It is important to note that, currently, only AWS offers this agentless interface capability among major global cloud platforms (both public and private clouds). This allows users to back up and synchronize cloud hosts without deploying agents. This mode not only simplifies operations but also reduces the impact on host performance.
Although Oracle Cloud also provides a similar solution, its implementation differs from AWS. Oracle Cloud does not offer this capability via REST API but instead uses low-level features of the SCSI (Small Computer System Interface) protocol to achieve agentless backup. This method is more complex in terms of integration and application compared to AWS's REST API.
For other cloud platforms like Microsoft Azure, Google Cloud, Alibaba Cloud, and Huawei Cloud, agent-based methods are still required for data synchronization. While these cloud platforms offer powerful cloud storage services, they do not yet support direct backup and data synchronization via REST API or similar agentless technologies. Therefore, users still need to use agents for incremental or full backups. To achieve agentless synchronization, cloud platforms would need to actively expose relevant APIs and capabilities, which are currently not available for agentless data synchronization.
In conclusion, AWS is currently the only cloud platform that supports agentless synchronization via EBS Direct API. This innovative feature provides users with a more convenient and reliable backup solution and contributes to the development of agentless backup technology in the cloud computing industry.
More details: Deep in AWS Agentless Mode
Huawei FusionCompute Agentless
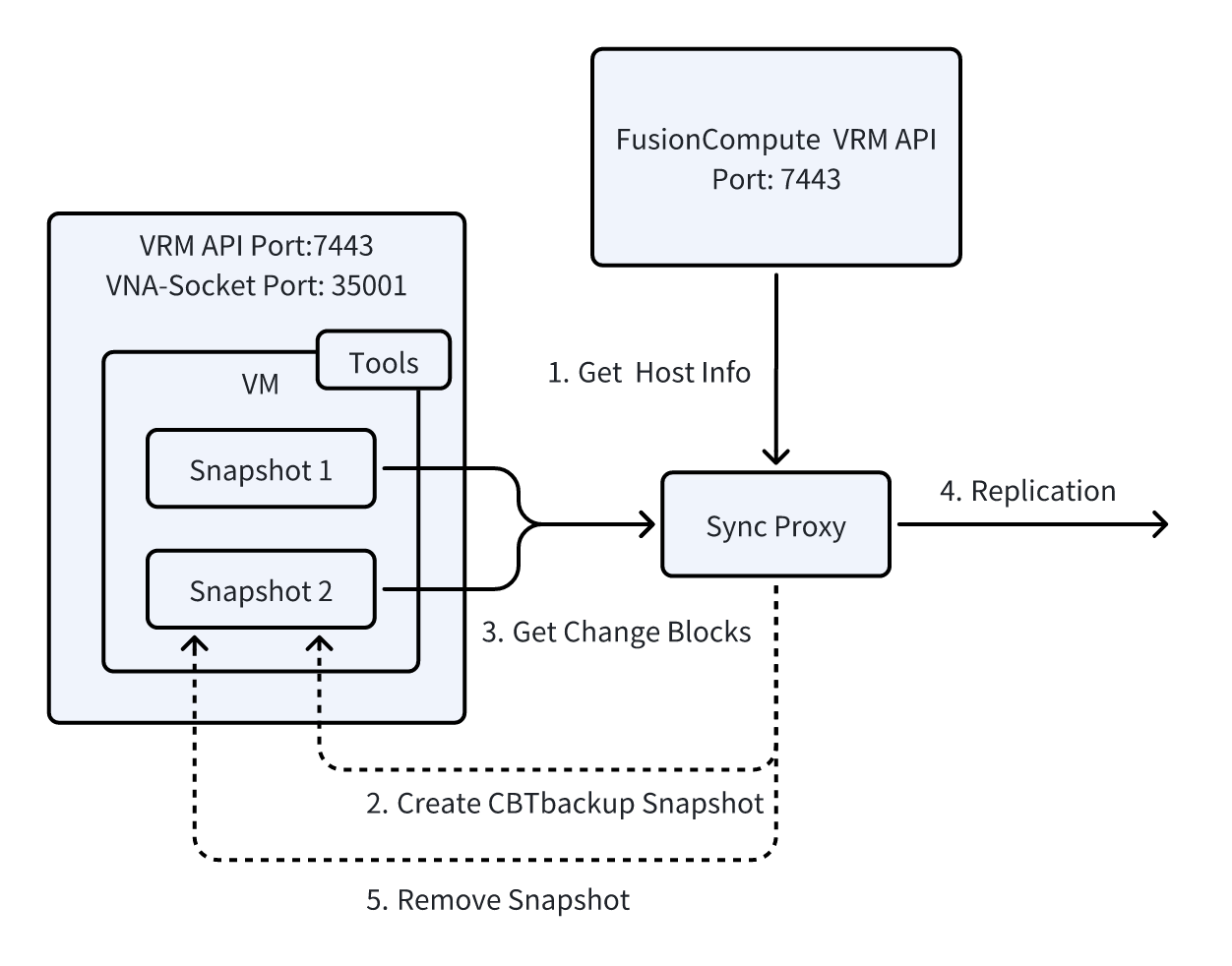
Huawei FusionCompute is a virtualization platform that supports agentless data synchronization. Its incremental snapshot function is similar to VMware's Changed Block Tracking (CBT) technology. FusionCompute uses APIs and socket interfaces to fetch incremental snapshot data for synchronization. Specifically, the API is used to request incremental snapshot information, while the socket interface is used for real-time transmission of the incremental data.
Unlike VMware, FusionCompute does not abstract the virtual machine storage layer (Datastore). VMware interacts directly with the virtual machine's disk (VMDK) through the hypervisor, allowing it to detect disk changes and perform incremental tracking. Therefore, to implement incremental snapshots (CBT), FusionCompute requires a lightweight agent to be installed on each physical host. This agent is responsible for monitoring the local host's storage layer and capturing incremental change data for each virtual machine. Due to the lack of a storage layer abstraction, FusionCompute relies on host-level agents as a supplement to achieve incremental synchronization similar to VMware.
Oracle Cloud Agentless
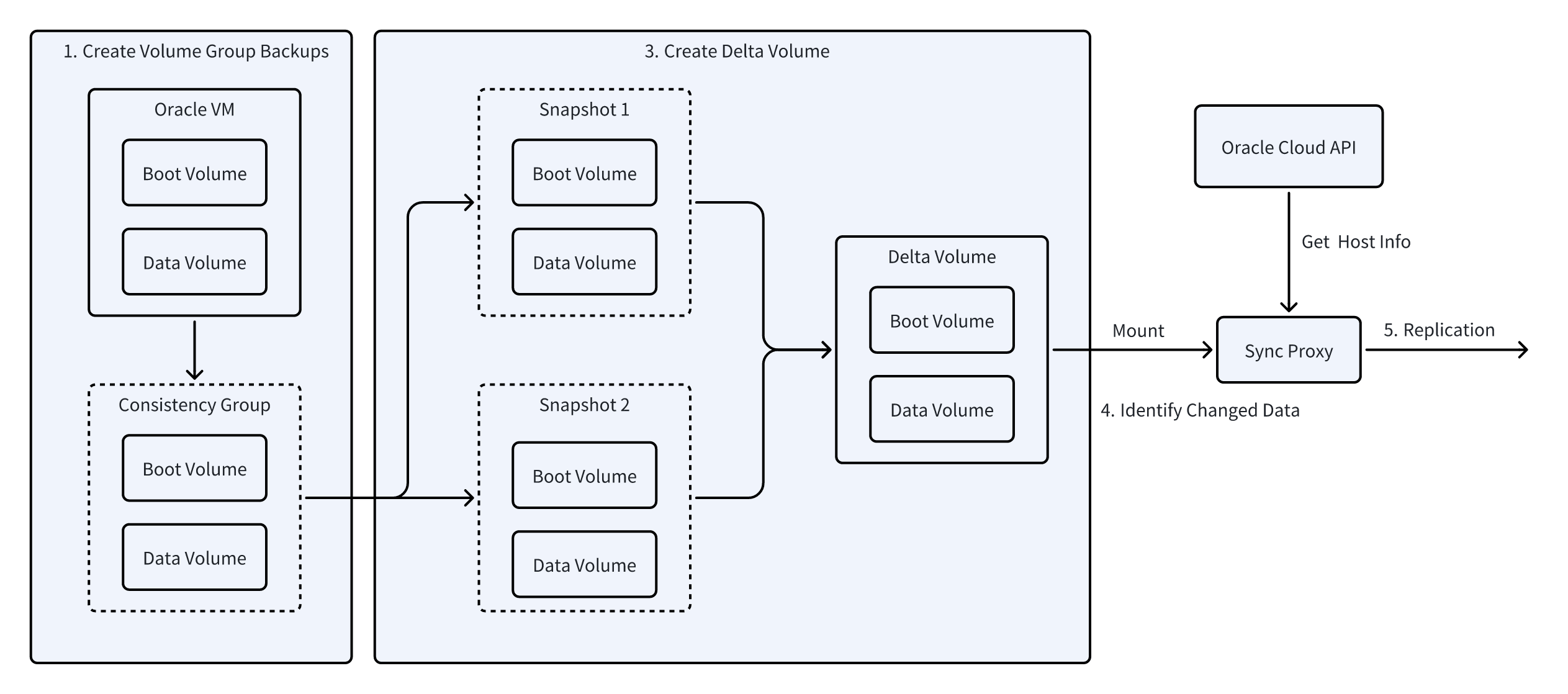
Oracle Cloud's agentless backup solution utilizes the SCSI protocol's GET LBA STATUS command to achieve block-level differential replication. This solution leverages the underlying hardware control capabilities of the SCSI protocol to accurately detect changes in data blocks on storage volumes. The implementation process is as follows:
- Create Volume Group Backups: To ensure data integrity, a consistent backup group for the host volumes is created first.
- Generate Incremental Volume: Based on the OCIDs of the previous and current backups, an incremental volume containing the changed data blocks is created.
- Mount Storage Volume: The incremental volume is mounted to a Linux instance using the iSCSI protocol.
- Identify Changed Data and Synchronize: The SCSI GET LBA STATUS command is used to scan the mounted volume, identify and extract the changed data blocks, and synchronize them to the target storage.
- Clean Up Resources: After synchronization, the volume is disconnected, unmounted, and deleted in sequence.
Reference
- Announcing OCI Block Volume Direct APIs for changed block tracking between backups
- Direct APIs for Changed Block Tracking Between Two Backups
Agentless vs Agent Mode
HyperMotion and HyperBDR support two deployment modes: Agentless and Agent-based. Select the mode that best fits your migration or disaster recovery requirements.
When to Use Each Mode
Agentless Mode (Recommended)
- Migration: Preferred for large-scale VM migrations and cross-platform migrations. Centralized control and block-level access improve efficiency.
- Disaster Recovery: Non-intrusive, centralized management with fast recovery and minimal operational overhead.
Agent Mode (Alternative)
- Special Environments: Use when nodes or operating systems don't support Agentless deployment, or when strict application/database integrity is required.
- High Consistency: Provides finer-grained control for critical applications and databases requiring high consistency guarantees.
Quick Decision Guide
- Large-scale environments or cost-sensitive operations → Agentless
- Critical applications or high database consistency requirements → Agent
- Migration efficiency priority → Agentless
- Fast recovery requirements → Both modes support
Feature Comparison
| Feature | Agentless Mode | Agent Mode |
|---|---|---|
| Deployment | No agent on protected nodes. Uses virtualization/cloud APIs for centralized management and data capture. Fast deployment, minimal dependencies. | Agent required on each protected node. Direct file system and application access for granular data capture and management. |
| Installation & Maintenance | No per-node installation. Centralized management, simple upgrades. Ideal for large-scale deployment. | Per-node installation, upgrade, and maintenance. Higher operational overhead, especially in large environments. |
| Deployment Prerequisites | No OS credentials, host security software configuration, or OS permissions required. | Requires OS username and password, host security software configuration (firewall, antivirus, etc.), and OS permissions (root/Administrator). |
| Resource Overhead | Low. No local CPU/memory usage. Minimal production impact. | Consumes local resources per node. Performance impact scales with node count. |
| Management | Low. Unified policy scheduling. No per-agent management required. | High. Track agent status, versions, and compatibility across nodes. |
| Capabilities | Block-level backup/recovery via cloud APIs. Centralized VM and volume protection. Suitable for large-scale virtualization or cloud environments. | File system, application, and database-level access. Supports granular backup strategies. |
| Consistency | Crash-consistent via storage snapshots. Suitable for fast VM and block data recovery. | Direct access to node systems and applications enables file system consistency. Windows platform with VSS provides limited application and database consistency. |
| RPO | Minute-level. Relies on snapshots or proxy node scheduling. Supports batch rapid data capture. | Minute-level. Agent executes backup policies with dynamic adjustment. |
| RTO | Supports Boot-in-Cloud automatic recovery. | Supports Boot-in-Cloud automatic recovery. |
| Security | Reduced attack surface. No additional software or open ports on nodes. | Increased risk. Agent requires ports and permissions. Additional security controls needed. |
| Operational Burden | Low. Centralized management, easy deployment and scaling. | Medium to High. Per-node deployment, monitoring, and upgrades. Higher costs in complex environments. |
Data Compression
Usage
Users can enable or disable compression in the synchronization settings before starting host synchronization. After selecting a host, navigate to the synchronization settings and toggle the compression option.
Compression is disabled by default to minimize resource consumption. To enable compression during synchronization, configure it before starting, or pause synchronization to change the setting.
How It Works
The system uses block-level data synchronization, dividing data into approximately 1MB blocks. When compression is enabled, each block is compressed during transmission to reduce network bandwidth usage.
Unlike file-level compression, our block-based approach means compression ratios vary based on operating system storage characteristics and data types. Text data typically compresses well, while images and binary data offer less compression potential.
The operating system's storage mechanisms can create a write amplification effect, where the actual synchronized data volume exceeds the original data volume. Compression helps offset this expansion rather than pursuing maximum compression ratios.
Compression Ratios
Compression effectiveness varies by data type. Since real environments contain mixed data, the following ratios are approximate:
- Text and structured data (logs, JSON, CSV): ~30% reduction
- Database files (MySQL/PostgreSQL data files, WAL, SQLite): ~10% reduction
- Pre-compressed media and binaries (JPEG, PNG, MP3/MP4, archives): <10% reduction
- Mixed application data (app directories, VM images, containers, cache): ~10–20% reduction, depending on composition
Note: These are conservative estimates. Actual results depend on data composition, write patterns, and OS storage mechanisms. Mixed data environments typically show lower compression benefits.
Transmission and Storage
During transmission, data is compressed before sending to reduce bandwidth, regardless of storage type.
- Block storage: Data is decompressed at the receiving end before storage, so storage usage exceeds transmission volume
- Object storage: Data remains compressed in storage and is only decompressed during recovery or reads, so storage usage matches transmission volume
This approach optimizes transmission efficiency while balancing storage usage and recovery performance based on the storage type.