HyperBDR Large-Scale Cross-Cloud DR Mexico IMSS 1,200 Hosts on Huawei Cloud Best Practices
HyperBDR Large-Scale Cross-Cloud DR Mexico IMSS 1,200 Hosts on Huawei Cloud Best Practices
1. Project Overview
1.1 Customer & Scenario
| Dimension | Description |
|---|---|
| Customer | IMSS (Mexican Social Security Institute) |
| Industry/Region | Social Security (Mexico) / Cross-Platform DR |
| Business Characteristics | Critical services for millions of citizens including healthcare, social security, and health management |
| Key Systems | Healthcare, social security, finance, HR, IT operations, data management |
| Business Scale | 1200 virtual machines |
| Host Disk Summary | Total disk capacity approx. 1760.56 TB |
| Source Environment | Huawei Cloud On-Prem HCS |
| DR Objectives | Rapid recovery in incidents, compliance with Data Protection and Digital Government laws; business continuity with RPO 15 minutes for critical systems and RTO within 30 minutes |
This project is a typical cross-platform cloud DR scenario and serves as a reference for government and public-service critical systems.
1.2 HyperBDR's Core Value in This Project
- Automated Batch Agent Installation: Automated scripts reduced agent deployment for 1200 hosts from 15+ days to 2 working days.
- Batch + Tiered Replication Strategy: Full sync in batches of 40–50 VMs/day, with incremental sync tiers of 15 minutes, 1 hour, 12 hours, 24 hours, weekly, and monthly.
- Boot in Cloud + Orchestration: One-click cloud recovery with dependency-based orchestration, enabling 10–15 minute bulk startup.
2. Business Challenges & HyperBDR's Response
Cross-platform cloud DR often faces the following challenges. This project addresses them with HyperBDR:
| Challenge | Description | HyperBDR's Response |
|---|---|---|
| Large-scale, complex systems extend deployment cycles | Over 1200 VMs across multiple resource pools, 7 Windows and 11 Linux versions, and very large data volume. | Automated batch agent installation and unified management to shorten deployment time and reduce manual complexity. |
| Strict compliance and high availability requirements | Healthcare and social security services require strict RPO/RTO and data privacy compliance. | Policy-based tiered replication for critical systems (15-minute RPO) and Boot in Cloud orchestration to meet a 30-minute RTO. |
| Heterogeneous environments increase migration difficulty | On-prem HCS and public cloud differ in platform and operations. | Unified HyperBDR replication and automated cloud-side resource provisioning for cross-platform DR. |
These challenges are common in cross-platform DR scenarios, making the practices in this project reusable.
3. HyperBDR Solution & Architecture
3.1 Overall Approach
Adopt a “batch migration + tiered replication + cloud-side orchestrated takeover” approach: complete full sync in batches, design multi-tier incremental RPO strategies by business criticality, and use Boot in Cloud with orchestration for rapid recovery.
3.2 Architecture Key Points
- Production: Huawei Cloud on-prem HCS with 1200 VMs across multiple business systems and OS versions.
- DR: Huawei Cloud public cloud with elastic compute and networking resources.
- Storage Layer: HyperBDR synchronizes on-prem data to cloud storage to support large-scale replication.
- Replication: Full sync in parallel batches; incremental sync tiers at 15 min / 1 h / 12 h / 24 h / weekly / monthly.
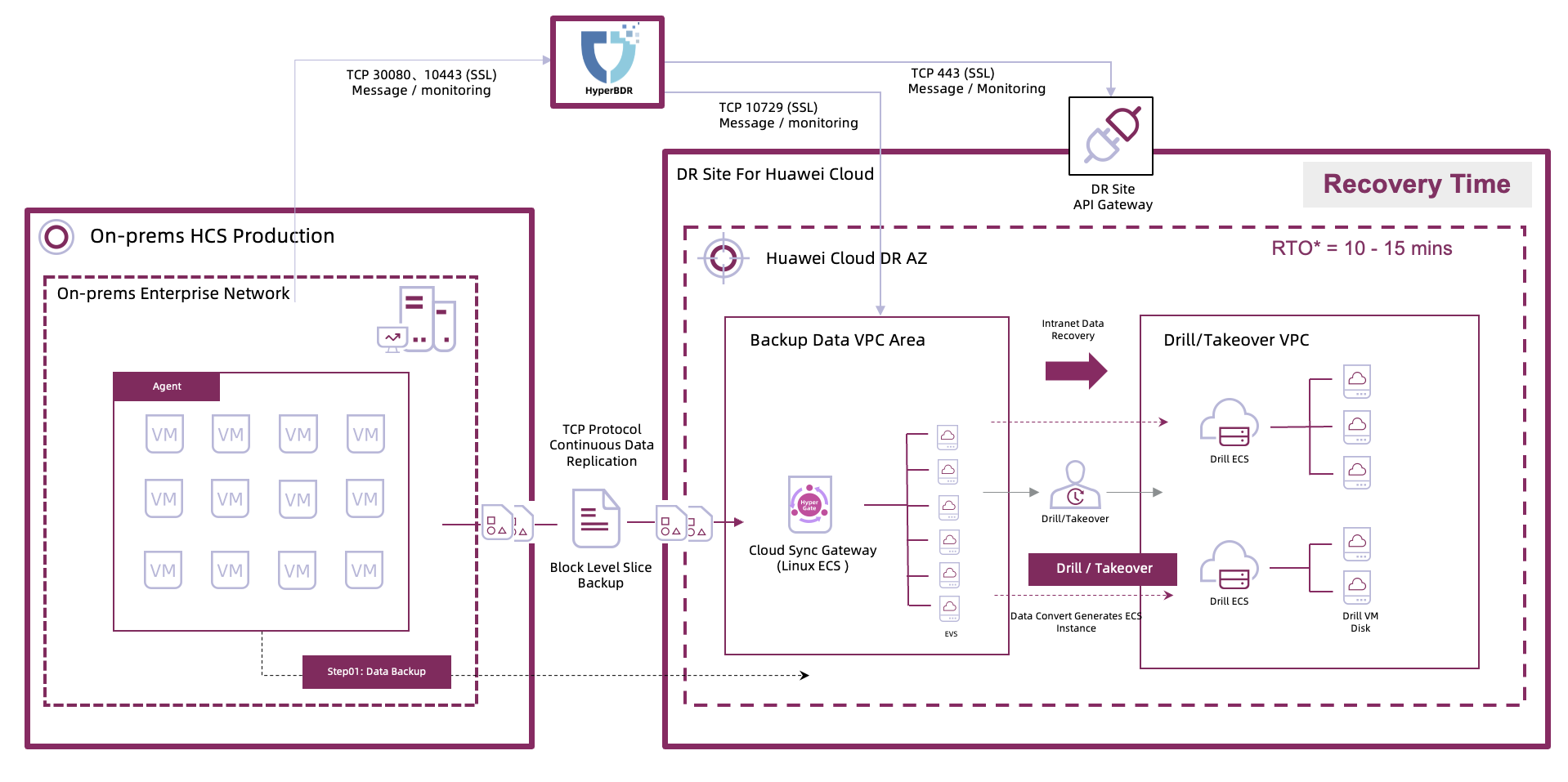
3.3 HyperBDR Core Capabilities in This Project
| HyperBDR Capability | Application in This Project | Value |
|---|---|---|
| Batch Migration | Execute full sync in 40–50 VMs/day batches | Balances network/storage pressure and ensures controllable progress |
| Policy-Based Synchronization | Tiered RPO policies by business criticality | Meets both critical and non-critical RPO targets efficiently |
| Boot in Cloud + Orchestration | Auto-create cloud resources and recover in dependency order | Bulk recovery in 10–15 minutes, meeting SLA requirements |
4. Implementation & DR Drill Best Practices
4.1 Data Replication Phase
In the pre-drill replication phase, this project adopts:
- Batch full replication: 40–50 VMs/day to reduce peak network/storage load.
- Tiered incremental replication: Critical systems at 15 minutes/1 hour, others at 12 hours/24 hours/weekly/monthly.
Continuous replication provides the data foundation for drills and takeover.
4.2 Drill & Takeover Phase Best Practices
Drills and takeover verify DR effectiveness. This project uses Boot in Cloud one-click takeover with the following steps and best practices:
4.2.1 Pre-Drill Preparation
| Step | Time | Key Actions | Purpose |
|---|---|---|---|
| Resource validation | T-1 day | Validate cloud quotas, connectivity, and security policies | Ensure drill environment readiness |
| Policy review | T-1 day | Review tiered replication policies and dependency order | Reduce drill interruption and rollback risk |
Key Points of Pre-Drill Preparation:
- Keep cloud-side images and network settings consistent with production.
- Define dependency priorities (databases before applications).
4.2.2 Drill & Takeover Phase
| Phase | Objective | Detailed Steps & HyperBDR Key Actions | Time & Results |
|---|---|---|---|
| Phase 1 | Start core systems | Trigger Boot in Cloud, auto-create cloud resources, start databases and core middleware | Core systems online within 10–15 minutes |
| Phase 2 | Start business systems | Orchestrate parallel startup of application and support services | Business services become available |
| Phase 3 | Validate & switch over | Validate consistency and availability, execute business takeover | Meet 30-minute RTO SLA |
HyperBDR Best Practice Points During Drill:
- Dependency priority: Start databases, authentication, and messaging first.
- Parallel recovery: Recover non-dependent systems in parallel to shorten overall time.
- One-click rollback: Enable fast revert after drills to minimize impact.
5. Key Results & Metrics
By adopting the HyperBDR cross-platform DR solution, the following outcomes are achieved during drills and takeover:
| Metric | Result | HyperBDR's Contribution |
|---|---|---|
| Deployment Cycle | Reduced from 15+ days to 2 working days | Automated batch agent installation and centralized management |
| RPO | 15 minutes for critical systems; tiered for others (1 h / 12 h / 24 h / weekly / monthly) | Policy-based synchronization and multi-tier scheduling |
| RTO | Bulk startup in 10–15 minutes; SLA 30 minutes | Boot in Cloud + orchestration automation |
6. Project Summary
This project verified HyperBDR's effectiveness in a cross-platform cloud DR scenario, delivering a reliable DR solution for IMSS. Key achievements include:
6.1 Key Achievements
- Efficient deployment: Agent deployment for 1200 hosts completed in 2 working days.
- Compliance and high availability: Meets strict compliance and HA requirements for public services.
- Rapid recovery: Bulk recovery within 10–15 minutes, meeting a 30-minute SLA.
6.2 Project Value
This project demonstrates HyperBDR's core value in cross-platform cloud DR:
- Improved resilience: Ensures continuity and data protection for public services.
- Reduced cost and complexity: Unified platform lowers operational and storage costs.
- High reusability: Applicable to large-scale DR in government and healthcare sectors.
6.3 Typical Scenarios
This project covers cross-cloud DR for critical public-service systems, serving as a representative reference for similar customers.